
To study by hand user queries for each of the solutions present on the 90 OVH group websites would take about 1034 days. 2.8 years.
As I explained in an interview (French) at Abondance.com, the acceleration of OVH worldwide requires us to question certain time-consuming practices in our SEO strategies.
By changing many letters to “time-consuming practices”, we obtain “automation”. Hey hey hey! To help me in my quest for “Automating Everything”, I decided to learn the R language .
One of the last tools I developed in R allows you to automate the creation of your content strategies, including keyword research, and that’s what you’ll find here.
Why you should automate your keyword research?
As I said, choosing the right keywords takes time, between 5 hours and 28 hours per project according to a study conducted by search marketer Paul Shapiro.
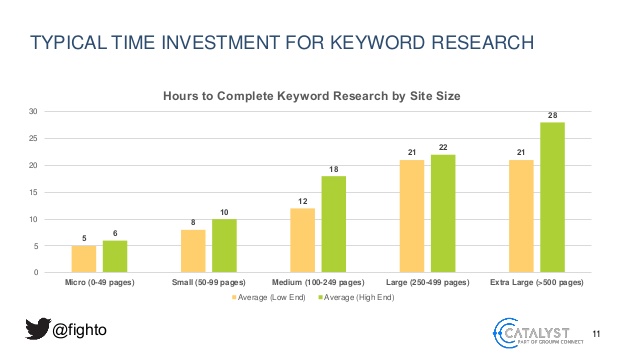
At a minimum, the operation consists in studying the needs of Internet users and their related queries, sorting them and qualifying them via different indicators such as purchase intent or search volume. It is then necessary to group them together in order to draw the foundations of a “SEO friendly” content strategy: the list of new pages to be created to cover a thematic and the list of pages you already have that need to be semantically optimized. ====> TAG SOMEONE WHO DOES IT EVERY DAY ON 80,000 ROWS EXCEL FILES!
Having been too many times this guy myself, I decided to react. This is my little TODO from the start:
- Automate the study of users requests
- Automate the creation of a list of new pages to create
- Automate the calculation of the potential of each new page
Method used
I had the opportunity to introduce the method at Web2day during my conference “Automation of an SEO strategy” of which you can find the french video below (RDV at 20:00 if you want to access the content strategy automation project)
To sum up, I divided the project into 5 main phases.
The first step is to get ALL requests that represent the thematic I want to cover. There are several ways to achieve near-exhaustiveness. Mine was to cross-reference data from several APIs, and that’s what I’m presenting in the video.
Once all the keywords have been recovered, a cleaning phase is required, followed by the preparation of the data for clustering.
In order to regroup the keywords together, I opted for the use of a hierarchical clustering algorithm. I used Jaro Winkler’s distance as a metric.
The principle is to measure the similarity between two strings. Other distances exist like Levenstein, Jaccard or Hamming but after several tests it is the distance of Jaro Winkler that gave me the best results.
Note that there are of course other methods on the side of natural language processing (NLP) to refine clustering, or the Google SERP study to regroup queries by search intent 😉 (I was talking about this subject in a Journal Du Net post (French))
Once the clusters are created, the next step is to measure the potential of each cluster by crossing the search volumes for each term with data from other tools such as analytics tools, the search console as well as data from web scraping but that’s another story….
Now you have the concept and goals in mind, let’s move on to the tutorial.
I will focus here on a simple and quick part to set up, and which also saves a lot of time: the creation of clusters. The R code you will find below should be executed directly in R Studio.
R script to create topic clusters from a keyword list
You can find the script as an R package on my Github account.
To test this script, you need a list of keywords. It must be an.xlsx file with a column called “Keyword” in which your keywords are located.
Start by loading the readxl and stringdist R packages
list.of.packages <- c("readxl", "stringdist")
new.packages <- list.of.packages[!(list.of.packages %in% installed.packages()[,"Package"])]
if(length(new.packages)) install.packages(new.packages)
library(readxl)
library(stringdist)
Now open the dataset in R Studio, using the following code:
#Votre liste doit être au format .xlsx
pathxlsx <- '/Users/remi/Downloads/keyword_list.xlsx'
df <- read_excel(pathxlsx,
sheet = 1,
col_names = TRUE,
na = "",
skip=0)
Let’s move on to the keywords clustering.
#1. Define the number of clusters you want to create kclusters = round(0.90 * length(unique(df$Keyword))) #2. Compute the distance between words uniqueThema <- unique(as.character(df$Keyword)) distancemodels <- stringdistmatrix(uniqueThema,uniqueThema,method = "jw")
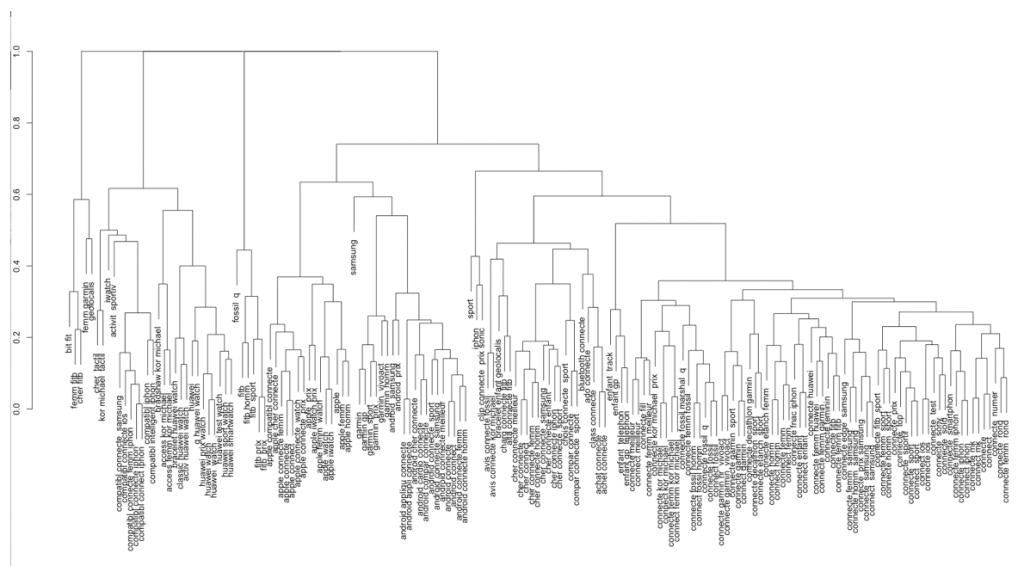
We can now display the dendrogram (= the word you have to tell everyone at your next raclette party!)
rownames(distancemodels) <- uniqueThema
hc <- hclust(as.dist(distancemodels))
par(mar = rep(2, 4)) #This line is used to avoid the error "figure margins too large"
plot(hc)
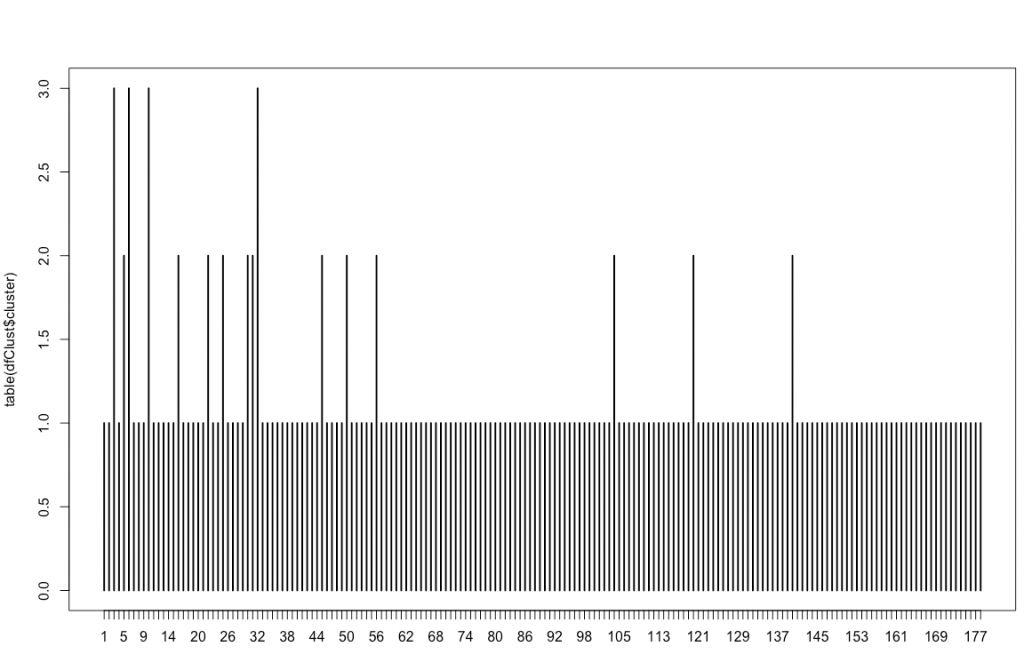
Create the file with the clusters associated with each keyword and display a graph with the number of keywords in each cluster:
dfClust <- data.frame(uniqueThema, cutree(hc, k=kclusters))
names(dfClust) <- c('Thema','cluster')
plot(table(dfClust$cluster))
Display your cluster file
View(dfClust)
Congratulations, you now have a basis to automate your keyword research and content strategies!
Feel free to try different clustering by changing the “0.90” of kclusters and enrich your script with, for example, taking inspiration from the features presented in the Web2day video.
PS: If you want to quickly develop your skills in data science for SEO, do not hesitate to register at the next Labs on Mars training.
Hello,
I just tried running this code, however, the text in the cluster tree and the bars in the bar graph are overlapping each other. Do you know of any fixes for this?
Thanks!
Is there a way to add brand names to the list of stop keywords? This is creating a one very large cluster with all brand keywords for me, so thinking that might be a solution. Thanks!