
Kévin Richard (SEObserver), Raphaël Doucet, David Carles, Christian Méline (Metamots), Anthony Técher (SEO Quantum) et Yann Sauvageon nous expliquent ici leur perception de l’IA dans le moteur de recherche Google et comment ils y font face concrètement dans leurs stratégies SEO.
Ces retours d’expériences regroupent une compilation de bonnes idées à mettre en place à l’heure de Rankbrain ainsi qu’une bonne dose de pistes techniques pour alimenter votre R&D. Il sera ici question de machine learning, de deep learning, de Word Embedding, d’ADN de page et de réflexions pour se mettre au niveau de Google et mieux comprendre l’intention de recherche. Si ces sujets vous intéressent, je vous invite à découvrir la formation SEO x Data Science.
Cet article est le deuxième d’une série de 3 articles dédiés à l’intelligence artificielle :
- Le cycle des IA 1 : Exploiter la big data pour le SEO
- Le cycle des IA 2 : Stratégies SEO pour faire face à l’IA (VOUS ÊTES ICI)
- Le cycle des IA 3 : 2022, quel futur pour le SEO ?
Faire face à l’intelligence artificielle Rankbrain
Lancée en 2015, la technologie de machine learning Google « Rankbrain » avait pour rôle initial d’améliorer la compréhension de nouvelles requêtes. Si elle est parfois difficilement perceptible, Rankbrain est aujourd’hui pourtant bien utilisée dans le classement des pages de résultats. Google a d’ailleurs annoncé que Rankbrain était le troisième facteur de positionnement le plus important, après les liens et le contenu.
« Le coup le plus rusé que l’IA ait jamais réussi, ça a été de faire croire à tout le monde qu’elle n’existe pas »
… Goddammit!
Servez-vous un autre café et passons aux avis d’experts.
Ressens-tu une montée de l’IA dans les SERP ? Si oui, quelles sont tes suggestions pour y faire face ?
Pour faire face à l’IA de Google, il faut retourner cette IA contre lui-même

La montée de l’intelligence artificielle dans les pages de résultats Google n’est même plus un ressenti, je vois clairement une montée en puissance de l’IA chez Google.
Google l’a affirmé à de nombreuses reprises et aujourd’hui, je constate une très nette amélioration des SERPs, c’est comme si le moteur réussissait à deviner l’intention de l’internaute, au-delà de critères extérieurs classiques (balise title, backlinks, etc).
Je mets par exemple au défi quiconque de m’expliquer au moyen d’indicateurs classiques pourquoi les requêtes « pecheur » ou « chaise longue » sont classées comme des requêtes de type marque, alors qu’aucun élément réellement discriminant n’est visible (que celui qui me parle d’optimisation d’ancres ou d’opti onsite regarde les requêtes serrurier).
Pour moi c’est grâce à l’IA et à travers l’analyse du comportement des internautes que Google ajuste automatiquement ses SERPs et qu’il ajuste des requêtes pour les faire passer, par exemple, de définition (pêcheur) ou de transactionnel (chaise longue) à une requête marque. Cela reste logique : l’internaute qui tape « pecheur » cherche en majorité à accéder au site pecheur.com et les autres cherchent des définitions, et c’est exactement la SERP que nous propose Google.
De manière globale, mon avis est que pour faire face à l’IA de Google, il faut retourner cette IA contre lui-même. Pour revenir sur l’exemple précédent, il me semble assez stratégique pour un consultant ou une agence de réussir à catégoriser correctement les mots-clés marque / hors-marque (ou plutôt navigationnels / non-navigationnels).
Et en y réfléchissant c’est tellement basique, notamment dans les analyses de type « analyse d’écarts » : en 2017 des outils continuent à faire des suggestions de type « vous êtes cdiscount.com, vous devriez vous positionner sur les mots-clés « amazon », « amazone », « amazon.fr », car ils ont un bon potentiel de visibilité, en effet le volume de recherche est élevé ! ».
D’ailleurs on parle souvent à tort de mots-clés « marque », mais on devrait plutôt parler de mots-clés navigationnels (navigational keyword).
Autre exemple, la clusterisation des mots-clés : sauf exception, Google réussit à « fusionner » les variante d’une requête (pluriels, accents, fautes de frappe, etc) et à les agglomérer dans des clusters plutôt cohérents. Pour analyser des requêtes et les classer entre elles, la fausse bonne idée consisterait à se baser sur la proximité des chaînes de caractères, mais cela n’a en réalité aucun sens. Au contraire, il faut utiliser l’IA de Google à fond.
Exemple d’absurdités :
« seo » et « senseo » ont 50% de caractères en commun ==> rangeons les ensemble !
« seo » et « search engine optimization » ont 0% de caractères en commun ==> ils sont totalement différents, hop 2 landing pages différentes ! (en réalité les SERPs sont similaires)
Plus tordu, « assurance auto » et « assurance auto entrepreneur » ont 2 mots sur 3 identiques ==> rangeons-les ensemble !
En réalité il s’agit de thèmes complètement différents (d’après Google assurance auto entrepreneur ne veut pas dire « une assurance auto pour entrepreneur », mais plutôt « une assurance pour auto-entrepreneur »).
L’approche « sémantique » classique, si on ose appeler ça comme ça, ne permet même pas de dégrossir, et peut induire en erreur. A mon avis elle est à éviter absolument. La seule approche valable à mes yeux est celle, coûteuse et longue, qui consiste à analyser les résultats de Google pour déterminer comment Google comprend la requête : utiliser l’IA de Google pour se positionner sur Google. (Note de Rémi Bacha : je vous ai parlé de cette approche reverse engineering dans l’article sur la Data Science SEO. Nous l’avons utilisé pour mieux connaitre les facteurs de ranking d’un site en particulier.)
Un des besoins fondamentaux de tout marketeur, et plus particulièrement les SEO, est de comprendre très rapidement de quoi parle une thématique, et de créer les landing pages pour récupérer du trafic. Et une personne normalement constituée peut digérer quelques centaines de « sous-thématiques » et certainement pas une liste de 20000 mots-clés à trier.
L’idéal serait de créer des clusters de mots-clés homogènes qui reflètent les mots-clés qui sont similaires pour Google et qui doivent se travailler absolument ensembles.
Nous sommes à l’heure actuelle en train de perfectionner un modèle automatique sur SEObserver, pour permettre à n’importe qui d’utiliser l’IA de Google pour faire son analyse de mots-clés et définir une stratégie de contenu SEO cohérente. Pour les plus nerds: l’approche consiste à prendre un mot-clé, récupérer tous les mots-clés proches en se basant sur les urls de la SERP, en créant ainsi un « cluster » de mots-clés, et de passer au mot-clé suivant, ainsi de suite. La petite subtilité, et c’est là qu’on parle de machine learning, est que nous faisons bouger les centres des clusters afin de faire plusieurs passes et recatégoriser comme il faut certains mots-clés qui auraient été attribués à tort à un premier cluster à cause de l’ordre de traitement des mots-clés par le script.
En guise de conclusion permets-moi de rappeller que le deep learning est un modèle « boîte noire » où, au lieu d’avoir une liste de curseurs, on peut ajouter dynamiquement des curseurs, et où le robot se charge de les découvrir tout seul et d’essayer des milliers, millions de modèles jusqu’à en atteindre un satisfaisant.
C’est d’ailleurs peut-être pour cette raison que Google a affirmé à plusieurs reprises qu’il était hors de question d’aller en totalité vers le machine learning, le debug est impossible. Gary Ilyes l’a explicitement dit et a lourdement insisté sur ce point lors de la conférence Digitalzone à Istanbul en 2016 :
Going all-in on machine learning is out of question for Google coz it’s impossible to debug what’s happening in SERPs @methode #digitalzone pic.twitter.com/pgsJSByp6I
— Kevin Richard (@512banque) 21 octobre 2016
La grande force de Rankbrain est l’interprétation des requêtes inconnues grâce au Word Embedding

L’IA peut « comprendre » et interpréter l’intention, ainsi que fournir le contenu le plus pertinent et le plus utile pour répondre aux besoins de l’internaute et à ces questions…et cela sur des millions de requêtes.
La grande force de Rankbrain est l’interprétation des requêtes inconnues grâce au Word Embedding. Avec l’arrivée de la recherche vocale, les utilisateurs se sont habitués à l’idée que Google « comprend » le langage naturel. S’il y avait deux algorithmes: l’un pour la recherche textuelle et le second pour la recherche vocale, nous pourrions ne pas nous en soucier de cette mise à jour. La réalité est que le texte et la recherche vocale sont alimentés par le même algorithme.
Pour résoudre le problème de la compréhension du langage naturel à l’aide de méthodes de deep learning, la problématique la plus importe est de transformer l’ensemble des mots en quelque chose d’interprétable par un ordinateur.
L’un des projets de Google est l’utilisation du Word Embedding au sein de son algorithme. Le Word Embedding converti des mots en vecteurs via un réseau de neurones.
L’utilisation du deeplearning permet à Google de prédire l’apparition ou non de terme dans le corpus étudié. L’objectif pour le moteur est de « valider » la fiabilité du contenu (et éradiquer le spam). Comment ça marche ? Les méthodes de Word Embedding construisent, pour chaque mot, une fenêtre de contexte. Au sein d’un corpus, un mot n’est pas utilisé de n’importe quelle manière, il est contextualisé : en relation avec les autres mots. C’est un aspect important visé par cette méthode : l’identification des relations entre les termes en calculant la distance entre eux. Il ne s’agit pas forcément de synonymes ou de cooccurrences : plus des termes apparaissent fréquemment les uns des autres, plus ils sont considérés comme proches.
Vous pouvez vous aider d’outil pour les trouver, c’est l’objectif de l’outil sémantique SEO Quantum : mimer le fonctionnement du moteur de recherche grâce au deeplearning afin d’obtenir la meilleure liste de lexies à employer pour un contenu performant.
Mon conseil : ne pensez plus mots-clés mais concept sémantique, Google les connait tous.
Il est important de noter que le regroupement des termes sémantiquement proche est loin d’être la seule chose que le Word Embedding permet. Le Word Embedding est capable d’apprendre des relations entre chaque mot d’un corpus, et de mesurer la «similitude» des mots, tant syntaxiquement que sémantiquement. Le plus impressionnant est que cette méthode permet d’identifier les « concepts » qui régissent nos écrits.

Grâce au Word Embedding, Google a appris que la relation entre l’homme et la femme est la même que la relation entre le roi et la reine (encodée dans le sens du vecteur en violet). Mais également le concept de « genre » et de « statut social » qui pourra réutiliser dans une autre thématique.
Le plus important, ces règles n’ont pas besoin d’être spécifiées. Le moteur les a appris en étudiant de grands corpus de texte via le « deep learning ». On comprend très vite que Google Rankbrain gère efficacement les requêtes de longue traine ainsi que les recherches totalement inédites puisqu’il n’utilise plus les mots-clés mais les concepts qui les caractérisent.
Voici un exemple de l’utilisation du word embedding dans le traitement des requêtes. Supposons un instant que vous avez oublié le mot « tutu » (et vous avez désespérément besoin de ce mot). Grâce aux vecteurs, vous pouvez googler « Danse vêtement Tchaikovsky » et Google va comprendre que Tchaikovsky fait partie du concept « ballet », puis modifier la requête en quelque chose comme « Quel vêtement de danse est en relation avec le ballet? » (ou, dans un discours vectoriel, « danse + vetement – ballet ») et cherchera la pièce manquante dans cette association.
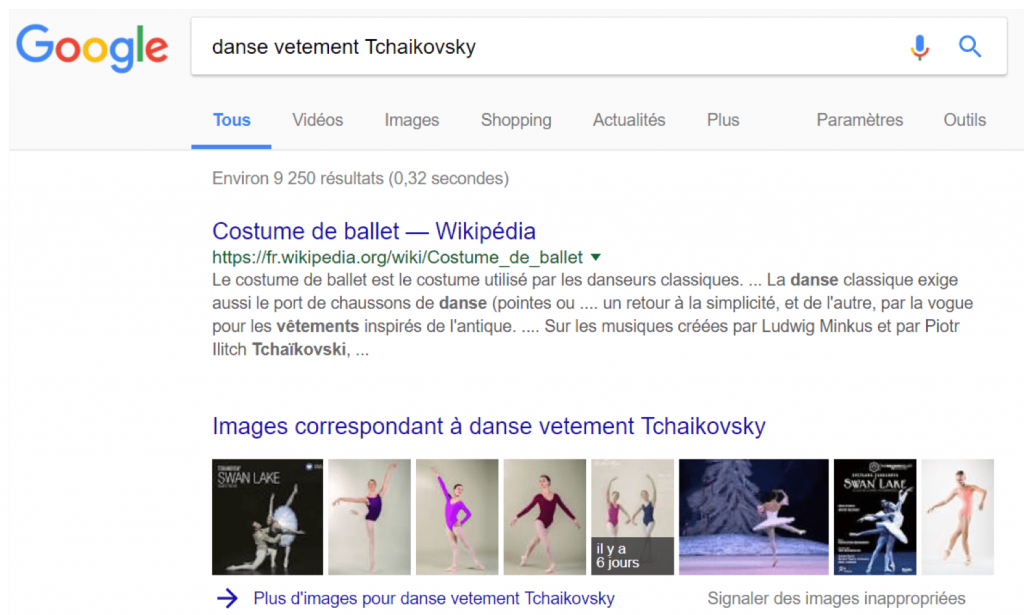
L’émergence du « deep learning » et du word embedding auront d’importantes conséquences dans notre travail de référenceur. Cependant, cela ne sonne pas la fin du référencement naturel. Nous devons nous adapter, adapter notre méthodologie et outils. Mais n’est-ce pas le propre du SEO ?
J’ai créé une méthode d’analyse du contenu qui imite la façon dont Google scanne les pages

Depuis plusieurs mois, les mouvements sont la seule chose certaine dans les SERP… Des mouvements de 10 ou 20 positions sont courants.
Malgré tout, nous jugeons souvent ces classements comme des SEO le font : sans personnalisation de la recherche. Il me semble que la stabilité est davantage au rendez-vous en cas de personnalisation.
Par contre, le point qui m’a le plus frappé est à quel point Google force la recherche par « nuage de sens » plutôt que littéralement. Quand on sait précisément ce que l’on veut, que l’on tape une partie de la réponse pour avoir la bonne SERP, dans ces cas précis Google semble perdu. C’est un peu comme s’il ne savait plus faire. Dans ces cas-là, il y a régression en termes de qualité de résultats.
Ces mouvements sont-ils dus à l’IA ?
Honnêtement, je n’en ai pas la moindre certitude. S’il est « aisé », avec de l’IA, de travailler à affiner des règles d’appréciation des sites, pour dégager les bons critères selon la thématique, ne serait-il pas très consommateur en ressources d’établir le classement qui s’en suit en IA ? Cela me semble hors de portée aujourd’hui, voir même inutile. En effet, l’internaute lui-même ne sait pas forcément ce qu’il cherche, être du coup trop précis, comme si on avait compris ce que lui-même ne sait pas, peut devenir contre-productif…
En admettant que cela soit utilisé pour le classement lui-même, vu l’importance de la personnalisation, il faudrait que chaque historique internaute soit passé dans la machine à décider réalisée en IA… même en regroupant par typologies d’historiques, cela me semble difficile de vouloir aller trop loin dans l’élaboration de la SERP elle-même avec de l’IA.
Par contre, je suis convaincu que chaque action internaute est passée au crible par Google et que cela alimente la connaissance que le moteur acquiert sur les intentions des internautes (pas forcément en IA, quoi que…). C’est cette conviction qui m’a amené à créer les metamots.
Essayons de trouver comment pourrait fonctionner un moteur de recherche à l’aune de ce que nous connaissons bien de nous-mêmes :
Regardons l’utilisation que nous faisons de notre intelligence, quand une situation nous est inconnue, nous sommes obligés de réfléchir. Mais une fois que cette même situation nous est devenue familière, nous procédons par procédures « prêtes à servir ». Il n’est plus besoin de réfléchir.
Si Google veut imiter notre fonctionnement, optimisé par mère nature, il peut faire de même : réfléchir quand il ne connaît pas pour l’établissement des règles, puis quand il connaît, faire de l’automatique (le classement lui-même, la SERP). L’analyse a posteriori des actions internaute est alors l’équivalent à l’introspection que nous faisons sur nous-mêmes a posteriori sur nos actions « de la journée »…
Depuis 2011-2012 nous travaillons sur ce que nous avons observé de l’importance que reprend peu à peu le contenu, et particulièrement le contenu textuel. Cela a donné les metamots qui sont précisément élaborés en partant du principe que Google a besoin de savoir si une page est en phase avec une requête personnalisée sans y passer trop de temps. Comme nous sommes partis du principe que Google ne voudrait pas passer 300 ans à comprendre une page, il fallait trouver quelque chose qui soit rapide, qui puisse fonctionner par « représentation instantanée » du contenu.
Nous avons imaginé que Google pourrait faire cela par prise d’empreintes, et il semble que nous ayons fait mouche : effectivement, Google ne semble même pas avoir besoin de comprendre un texte pour décider si une page est « pertinente », une simple empreinte (sorte d’ADN de la page), permet de le savoir sans même faire de « sémantique » au sens propre.
Les metamots sont donc des empreintes. Il s’agit d’un profilage sur quelques lexies soigneusement choisies dans la langue. Par rapport à une requête « reformulée par Google », lesquelles peuvent aller ensemble, ou pas, voir leur attirance plus ou moins forte pour la requête, etc.. Chaque metamot est élaboré sur la base de data réelle.
Dans les faits, le signal envoyé semble convenir à Google, notamment dans le cas de maillage dit « sémantique ». Pour autant la R&D continue !
Les concepts fondateurs des metamots ont d’ailleurs été repris par Google dans un brevet déposé en septembre 2016.
Toutefois, nous ne considérons pas les metamots comme une méthode sémantique au sens propre. Ils sont plus à rapprocher à du traitement de signal…
La meilleure stratégie SEO consiste à comprendre l’intention de recherche

L’un des tournants pour moi à ce niveau c’est l’arrivée de RankBrain. Lors d’une conférence dans ses locaux parisiens en début d’année 2017, Google a avoué qu’avant cela il « ne comprenait pas vraiment les requêtes des internautes » et qu’aujourd’hui il « commencait à avoir une compréhension sémantique des informations ».
On peut voir apparaitre de nouvelles fonctionnalités comme la position 0 (expliqué sur mon blog) ou encore les PAA aux USA. Google, par apprentissage, essaye de deviner l’intention de recherche de l’internaute, pour lui proposer une réponse directe quand cela est possible. Certes le système est encore perfectible (toujours en apprentissage), mais il faut se rappeler qu’avant ce type de réponse n’existait que pour les définitions.
Aujourd’hui, Google, avec ses millions d’analyses de comportements tente d’apporter une réponse statistique. Si vous effectuez la requête « gâteau au chocolat », vous allez très certainement vous retrouver avec une position 0 sous forme de recette. Google a appris, que statistiquement pour ce genre de requêtes, les internautes voulaient une recette de gâteau au chocolat. Pour les PAA c’est la même chose, Google propose des questions (et réponses) complémentaires à une requête, car statistiquement les auteurs de ce types de requêtes posaient également ces questions. Le challenge de Google est de comprendre l’intention finale de l’utilisateur pour lui proposer une réponse adaptée et ce parfois même avant qu’il n’en émette le souhait.
Comment en tirer partie?
Selon moi, la meilleure stratégie à mettre en place doit se baser sur la compréhension de l’intention qui se cache derrière une requête ou un pool de requêtes afin de proposer le bon contenu, au bon moment, au bon endroit et sous la bonne forme. Rien de bien nouveau en soit, sauf que Google accélère de plus en plus dans ce sens et l’analyse de données (manuelle ou industrielle) vous guidera dans vos décisions.
Si nous reprenons l’exemple des positions 0, après l’étude de 12 millions de mots clés grâce à SEMrush, il en ressort que 61% des P0 avec une requête comprenant « comment » contiennent une liste. Il va donc de soit, que dans notre réponse, une partie du contenu devra être agencé sous cette forme pour augmenter les probabilités d’apparition.
Google utilise la sémantique et les cooccurrences pour désambiguïser certaines informations. Il utilise également des notions de TF-IDF pour classifier les documents. Pourquoi ne pas faire les mêmes analyses afin d’enrichir nos contenus avec ce qu’il attend. C’est là que des outils comme 1.fr, Yourtext.guru, Seoquantum.com ou les MetaMots sont utiles. En se basant sur l’analyse des résultats retournés, ses outils sont capables d’identifier les termes attendus par Google.
Si Google comprend et identifie les contenus des médias (images, vidéos…), on voit clairement qu’on ne peut plus simplement se contenter de balancer la première image ou vidéo qui traine juste pour illustrer une page. Pourquoi ne pas penser retargeting, et mettre dans le média des objets pour lesquels Google proposera d’autres de nos supports de visibilité (Adwords, contenu en relation…)
Chaque requête d’internaute déclenche ses propres ranking factors

Le développement de l’intelligence artificielle chez Google et son intégration au sein de son algorithme est sans aucun doute l’une des actualités SEO les plus passionnantes des dernières années.
Le fait que les algorithmes deviennent de plus en plus intelligents exige conséquemment de revoir le plus rapidement possible les stratégies SEO jusqu’ici employées.
Si on revient quelques années en arrière, l’annonce de Google sur le RankBrain peut être vue comme un point tournant majeur dans l’histoire du SEO. Jusqu’à ce moment plutôt discret sur l’utilisation du AI, Google annonce alors que son algorithme fonctionne de façon presque autonome, et possède les capacités de comprendre l’intention derrière un mot-clé jusqu’ici jamais utilisé sur le moteur de recherche.
Surtout, RankBrain devient alors une preuve sans équivoque de la suite pour le moteur de recherche californien : Google possède la puissance nécessaire pour que son algorithme développe constamment ses connaissances. Le spécialiste SEO doit donc mettre à jour son arsenal et ses techniques, mais surtout revoir certaines mentalités et croyances qui ne s’appliquent déjà plus.
Voici à mon avis les principaux changements auxquels le spécialiste SEO doit faire face suite à la montée de l’intelligence artificielle dans les résultats de recherche.
– Réaliser que l’analyse régressive des mises à jour d’algorithmes est maintenant devenue une perte de temps, alors que chaque mot-clé et donc ses résultats possèdent en quelque sorte leur propre algorithme, chacun basé sur des facteurs pouvant être différents d’une recherche à une autre (Note de Rémi Bacha : Consultez la vidéo de notre conférence à l’OVH Summit 2017, sur ce sujet). RankBrain, et son machine learning, peut réorganiser constamment les résultats sous une requête, différemment d’un autre ensemble de résultats pour un autre mot-clé.
– Il faut également continuer à porter une attention à l’expérience offerte au visiteur, avec comme base le CTR organique dans les résultats de recherche, mais également le temps passé et l’engagement sur la page de destination, et si celle-ci a répondu aux attentes du chercheur. Google possède la puissance requise ainsi que les données nécessaires pour suivre le parcours de chaque utilisateur de son moteur de recherche, dès le moment de la requête, jusqu’à ce que celui-ci ait trouvé la réponse à sa recherche.
– Également, il faut assurer que le site est le plus niché possible en lien avec un sujet, afin de faciliter la classification de celui-ci. Si votre site couvre plusieurs thématiques de contenu différentes, comment est-ce que l’algorithme pourra décider votre thème dominant, et ainsi le classer dans la bonne industrie ?
– La richesse du contenu et le fait d’y inclure les synonymes et termes variables n’est pas une stratégie nouvelle, mais elle est impérative dans une ère dominée par l’intelligence artificielle. L’optimisation sous un mot-clé exact est révolue, il faut penser thématique, et inclure les recherches complémentaires suggérées par Google à même les résultats de recherche. À noter que cette approche est également recommandée dans le cas d’une stratégie d’optimisation vocale.
– Ils le sont déjà, mais je crois que les facteurs techniques sont appelés à prendre de plus en plus d’importance, avec en tête de liste le temps de chargement et la gestion efficace du budget d’optimisation (crawl budget). Pensez à faire des analyses de logs régulièrement.
L’IA va tenter de suggérer de nouveaux critères cognitifs pour classer les pages

Les conséquences évidentes de l’IA sur le Search seront le fait que les moteurs de recherche, et Google en premier lieu, se baseront de moins en moins sur une liste de facteurs prédéterminés.
Rankbrain, notamment, fonctionnerait comme un DJ qui, s’adaptant à son “audience”, choisirait de tourner telle ou telle “potentiomètre” pour rendre la soirée unique. Les “potentiomètres” de Rankbrain sont les différentes données auxquelles il a accès et leurs poids associés. Son “audience” est quant à elle constituée de chaque couple requête/utilisateur qui se présente a lieu. L’IA entraîne donc une plus grande malléabilité des facteurs de ranking, qui n’ont pas le même poids d’une requête à l’autre, l’algorithme adaptant en permanence son modèle ARL (Association Rule Learning).
Le déclassement de certains facteurs au profit de facteurs « cognitifs », la mutation permanente des facteurs avec la montée en puissance de l’IA et l’augmentation des données disponibles
Avec l’IA, certains facteurs historiquement importants en SEO seront probablement déclassés au profit de nouveaux facteurs. Ces algorithmes auto-apprenants qualifiés d’IA (Automated Machine Learning, Deep Learning) vont tenter de suggérer de nouveaux critères “cognitifs”, plus en rapport avec les éléments déclencheurs de satisfaction chez un internaute.
Rankbrain n’est pour l’instant qu’une « Artificial Narrow Intelligence » (ANI), une IA étroite en français. Il est fort probable que cette IA gagnera en capacités dites cognitives dans les mois et les années à venir. Ces nouvelles capacités permettront de tester et traiter de nouvelles catégories de facteurs. Dans un contexte de montée en puissance des interactions vocales et visuelles, que ce soit via les smartphones ou les fameux smart speakers, on peut, par exemple, imaginer que l’IA décidera (ou tout du moins tentera) de donner du poids à de nouvelles typologies de données qui n’existaient pas auparavant (la voix, la tonalité de la voix, l’accent d’une voix, la reconnaissance des visages, la reconnaissance des sentiments via la voix et les images,…).
Alors, certains experts prédisent que le SEO va être radicalement changé par l’IA, qu’il deviendra en conséquence de plus en plus complexe. Oui et Non.
Oui, car en tant que SEO, nous pouvons désormais nous même utiliser ces outils de Machine Learning pour deviner les critères les plus importants, pour prédire l’impact de nos modifications sur les résultats. La manière de travailler des SEO pourra impliquer une plus grande utilisation d’outils de machine Learning, notamment avec la démocratisation d’outils accessibles aux non-codeurs (BigML, Dataiku, DMWay, Datarobots…) et l’apparition d’outils ML et prédictifs directement applicables au SEO (Marketbrew.com).
Non, car finalement, tout cela ne change pas vraiment le métier du SEO, dont un des principaux attributs est de savoir s’adapter à des critères changeants et à ne pas se reposer sur des règles figées et apprises dans le passé. Avant d’être un monsieur-je-sais-tout, le SEO doit être un spécialiste de la résolution de nouveaux challenges (la liste est longue, Panda, Hummingbird, Mobile-Friendly, Knowledge Graph, l’index mobile-first, la position zéro…) et doit se former en continu pour rester sur le haut de la vague.
Ne ratez pas la dernière partie du cycle des IA
Le 3ème épisode du cycle des IA est disponible ici : 2022, quel futur pour le SEO ?
. Nous y aborderons les évolutions possibles du search et de l’avenir du métier de SEO avec la montée de l’IA. Vous verrez, l’idée sera d’aller encore un peu plus loin dans le prospectif.
Je compte sur vous pour commenter l’article, le partager s’il vous a plu et à me rejoindre sur sur Twitter :
Superbe article, interviews excellentes.
Je rebondis sur les requêtes non-navigationnelles proposées par Kevin.
Dans le cas de la « chaise longue », Google comprend que c’est une requete d’achat.
Cependant pour optimiser la page et montrer à Google que ce n’est pas un site d’information mais un site d’achat, quelles sont les possibilités? Travailler sur du clustering type « acheter chaise longue », « chaise longue prix », etc. ou plutôt travailler sur le clustering « chaise pecheur » ; « comment s’asseoir à la peche » ; « pecher debout ou assis, telle est la question » ?
merci!
Bonjour Remi merci tout d’abord pour ce partage 🙂 j’ai visionné avec attention votre video Youtube https://www.youtube.com/watch?v=5iDBW3F_cYM vous parlez de votre outil opensource DATAIKU DSS vous confirmez que cet outil dont vous parlez ?
Quelle est l URL de cet outil que l on peut utiliser ?
merci par avance
Hello Hady,
il s’agit bien de Dataiku DSS dans la vidéo. J’avais écrit un tuto sur l’utilisation de Dataiku pour des analyses de logs poussées : https://remibacha.com/analyse-logs-ovh-dataiku/
Tu y trouveras tout ce qu’il te faut pour démarrer avec l’outil.
Un bel article qui montre le niveau d’expertise et de R&D que nous avons la chance d’avoir en France. Merci pour cette vulgarisation efficace, comme de comparer RankBrain à un DJ !
Voilà de quoi prendre du recul.
Cette fois c’est clair, l’homme se bat contre la machine !
Bonjour, Article Intéressant.
Pour moi, il y a deux parties dans l’intelligence prétendu par Google :
1. Le Knwoledge Graph qui répertorie les données sous forme d’entités suivant des critères Google, prédit les compléments des requêtes de recherches, organise et annote les contenus par des tags comme événements, Place….
2. le système basé sur l’intelligence artificielle « rankbrain » qui utilise un supercalculateur Tensor Processing Unit capable de traiter rapidement une complexité. Le rôle du RankBrain est essentiellement d’apprendre et de réguler le positionnement et la visibilité ou non des documents.
Bien entendu il faut un point de départ pour toute intelligence, le Knwoledge sert comme univers au Rankbrain, toute entrée d’entité est exploitée par le rankbrain dans le cas d’une requête comportant une entité.
dans le cas ou la requête ne comporte pas d’entité, c’est à ce moment là qu’on pourrait voir le RankBrain en Action.
suivant ce que je vois et ce que j’en conclu, le coeur de l’algorithme de google qui à part l’injection du Panda et du Penguin n’a pas beaucoup changé de se version Caffeine, il produit dans son état actuel des résultats pertinents, il ne sera pas donc délaissé par google, au contraire il est le générateur de base des résultats s’appuyant sur les facteurs dites SEO qu’on connait tout le monde. De ce fait, RankBrain agit en deux sens, le coté utilisateur dont il puise des nouvelles requêtes pour se poser les questions et créer des équations, et le coté contenu proposé et qui déclenche les acquis de l’apprentissage pour solutionner les équations si nécessaire suivant son Intelligence.