
Étudier à la main les mots-clés pour chacune des solutions présentes sur les 90 sites web du groupe OVH demanderait environ 1034 jours. 2,8 années.
Comme je l’expliquais dans une interview chez Abondance.com, l’accélération d’OVH à l’international requiert de remettre en question certaines pratiques chronophages dans la conception des stratégies SEO.
En changeant beaucoup de lettres à « pratiques chronophages », on obtient « automatisation ». Hé hé ! Pour m’aider dans ma quête du « Tout automatiser », j’ai décidé d’apprendre le langage R.
L’un des derniers outils R que j’ai développé permet d’automatiser la création de ses stratégies de contenus, notamment la recherche de mots-clés, et c’est ce que vous allez découvrir ici.
Pourquoi automatiser sa recherche de mots-clés ?
Comme je vous le disais, choisir les bons mots-clés prend du temps, entre 5 heures et 28 heures par projet selon une étude réalisée par le search marketer Paul Shapiro.
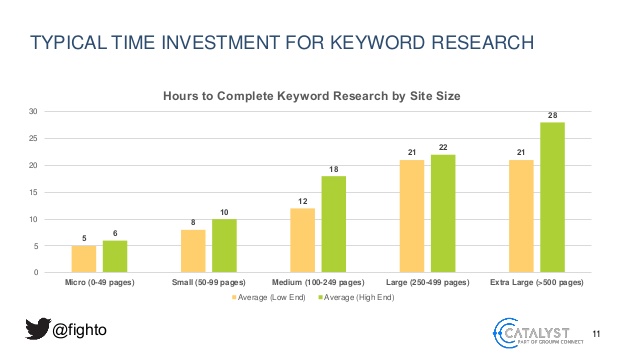
Au minimum, l’opération consiste à étudier les besoins des internautes et leurs requêtes associées, les trier et les qualifier via différents indicateurs comme l’intention d’achat ou le volume de recherche. Il convient ensuite de les regrouper afin d’en tirer les fondations d’une stratégie de contenus « SEO friendly » : la liste des nouvelles pages à créer pour couvrir une thématique et la liste des pages egixistantes à optimiser sémantiquement. ===> TAGUE UN POTE QUI FAIT ÇA TOUS LES JOURS SUR DES FICHIERS EXCEL À 80 000 LIGNES !
Ayant moi-même été de trop nombreuses fois ce fameux « pote », j’ai décidé de réagir. Voici ma petite TODO de départ :
- Automatiser l’étude de requêtes d’internautes
- Automatiser la recherche de pages à créer
- Automatiser le calcul du potentiel de chaque nouvelle page
Méthode utilisée
J’ai eu l’occasion de présenter la méthode au Web2day lors de ma conférence « Automatisation d’une stratégie SEO » dont vous pouvez retrouver la vidéo ci-dessous (RDV directement à la 20ème minute si vous souhaitez accéder au projet d’automatisation de la stratégie de contenus)
En résumé, j’ai découpé le projet en 5 grandes phases.
La première est la récupération de TOUTES les requêtes qui représentent la thématique sur laquelle je veux travailler le SEO. Il y a plusieurs façons d’atteindre une quasi-exhaustivité. La mienne a été de croiser les données de plusieurs API, et c’est que je présente dans la vidéo.
Une fois tous les mots-clés récupérés, une phase de nettoyage s’impose, suivie de la préparation des données pour la clusterisation (à ce propos, si vous cherchez des scripts R pour préparer un dataset, allez voir du côté de mes articles « Data pre-processing avec R [Mode Zombie] » et « Préparer sa liste de mots-clés SEO avec R« ).
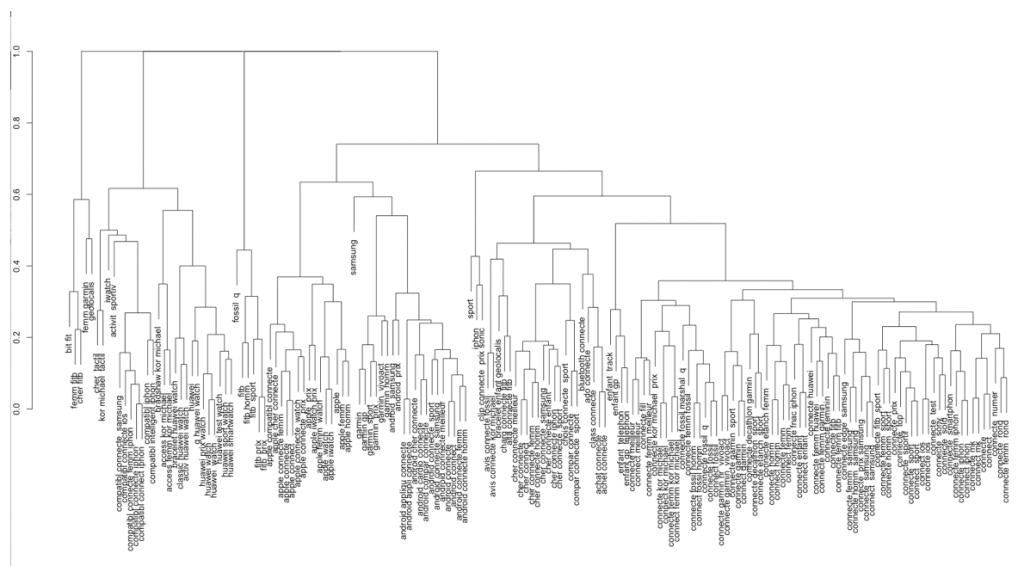
Afin de regrouper les mots-clés ensemble (la fameuse « clusterisation ») j’ai opté pour l’utilisation d’un algorithme de regroupement hiérarchique (Hierarchical Clustering) avec lequel j’ai utilisé la distance de Jaro Winkler comme métrique.
Le principe est de mesurer la similarité entre deux chaines de caractères. D’autres distances existent comme Levenstein, Jaccard ou Hamming mais après plusieurs tests c’est la distance de Jaro Winkler qui m’a donné les meilleurs résultats.
Notez qu’il existe bien sûr d’autres méthodes du côté du traitement automatique du langage naturel (NLP) pour affiner la clusterisation ou encore l’étude de la SERP Google pour regrouper les requêtes par intention de recherche 😉 (Je parlais d’ailleurs de ce sujet dans un article du JDN)
Une fois les clusters créés, la suite consiste à mesurer le potentiel de chaque cluster en croisant les volumes de recherches pour chaque terme avec des données d’autres outils comme les outils d’analytics, la search console ainsi que des données issues de web scraping mais c’est une autre histoire…
Maintenant que vous avez bien le concept et les objectifs en tête, passons au tuto.
Je vais m’attarder ici sur une partie simple et rapide à mettre en place, et qui en plus permet de gagner beaucoup de temps : la création de clusters. Le code R que vous trouverez ci-dessous est à exécuter directement dans R Studio.
Script R pour regrouper ses mots-clés
Vous pouvez récupérer le script sous la forme d’un package R sur mon compte Github.
Pour tester ce script, il vous faut une liste de mots-clés. Il doit s’agir d’un fichier .xlsx avec une colonne intitulée « Keyword » dans laquelle se trouvent vos mots-clés.
Commencez par charger les packages R readxl et stringdist
list.of.packages <- c("readxl", "stringdist")
new.packages <- list.of.packages[!(list.of.packages %in% installed.packages()[,"Package"])]
if(length(new.packages)) install.packages(new.packages)
library(readxl)
library(stringdist)
Ouvrez maintenant le jeu de données dans R Studio, grâce au code suivant :
#Votre liste doit être au format .xlsx
pathxlsx <- '/Users/remi/Downloads/keyword_list.xlsx'
df <- read_excel(pathxlsx,
sheet = 1,
col_names = TRUE,
na = "",
skip=0)
Passons à la clusterisation des mots-clés.
#1. Définissez le nombre de clusters que vous souhaitez créer kclusters = round(0.90 * length(unique(df$Keyword))) #2. Calculez la distance entre les mots uniqueThema <- unique(as.character(df$Keyword)) distancemodels <- stringdistmatrix(uniqueThema,uniqueThema,method = "jw")
On peut maintenant afficher le dendrogramme (= le terme à placer lors de votre prochaine soirée raclette !)
rownames(distancemodels) <- uniqueThema
hc <- hclust(as.dist(distancemodels))
par(mar = rep(2, 4)) #Cette ligne permet d'éviter l'erreur "figure margins too large"
plot(hc)
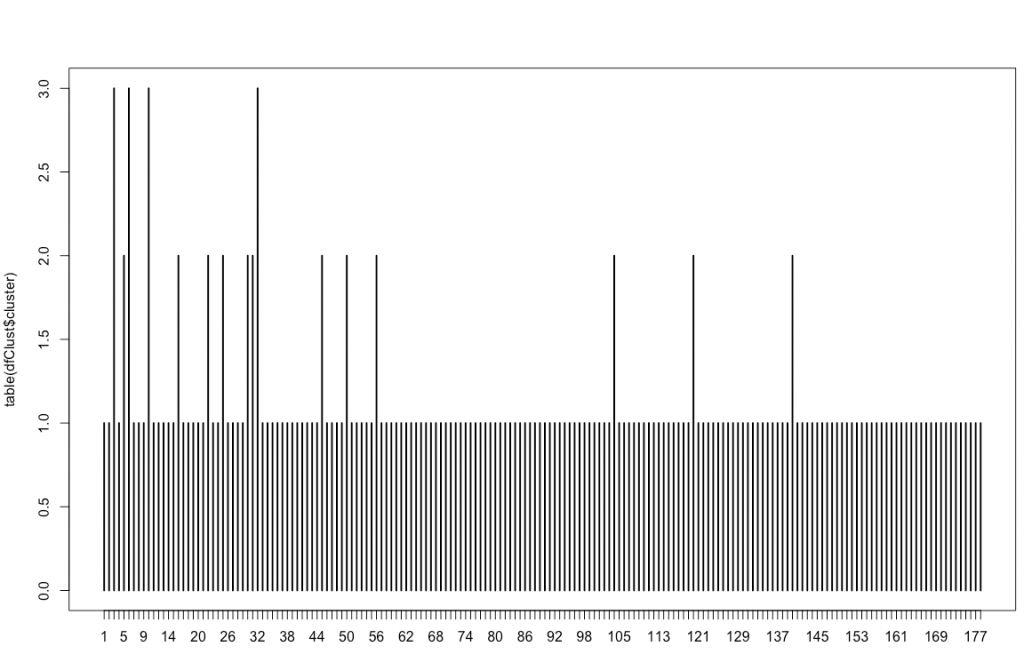
Créez le fichier avec les clusters associés à chaque mot-clés et affichez un graph avec le nombre de mots-clés dans chaque cluster :
dfClust <- data.frame(uniqueThema, cutree(hc, k=kclusters))
names(dfClust) <- c('Thema','cluster')
plot(table(dfClust$cluster))
Affichez votre fichier de clusters
View(dfClust)
Bravo, vous avez maintenant une base pour automatiser votre recherche de mots-clés et vos stratégies de contenus !
N’hésitez pas à essayer différentes clusterisation en changeant le « 0.90 » de kclusters et à enrichir votre script en vous inspirant par exemple des fonctionnalités présentées dans la vidéo du Web2day, plus haut dans l’article.
PS : si vous souhaitez développer rapidement vos compétences en data science, n’hésitez pas à vous inscrire à la prochaine formation Labs on Mars.
Salut Rémi
Bon article et en plus bonne conférence à la Web2Day Bravo ( je l’est vue en direct), on c’est dit bonjour vite fait, en tous les cas bon article j’aime tes articles, la prochaine on se boit un coup, à la web2day moi j’ai été occupé en plus avec ma conf etc … mais la prochaine avec plaisir. Bravoo encore.
Hello Maher, ca fait plaisir, content que la conf te plaise ! On se recroisera forcément a un événement SEO 😉
Super tuto, je teste actuellement ton package pour les clusters mais j’ai du mal à exploiter le résultat. J’obtiens la même liste keywords avec une colonne en plus qui va de 1 à 76.
Pourrais tu expliquer l’usage du fichier en sortie stp ?
Hello Martin,
La nouvelle colonne est la liste de tes clusters. Je t’invite à classer la colonne par ordre croissant. Chaque mot-clé à été rattaché à un cluster et le numéro présent dans la nouvelle colonne est en quelque sorte l’ID de ce cluster. N’hésite pas à modifier le ratio pour tester différentes clusterisations.
Je n’arrive toutefois pas à attribuer une thématique avec le nombre de keywords à chacun des clusters comme on le voit dans le vidéo. Des orientations?
zrsgbfrklwnieqxyfvdowzxdqdwina