
Dans tout projet de Data Science, une étape INDISPENSABLE s’impose : la préparation des données.
Vous allez découvrir ici une liste de scripts en langage R, prêts à l’emploi, pour transformer et préparer vos jeux de données. Pour celles et ceux qui découvrent le R, n’hésitez pas à commencer par lire l’article « utiliser le langage R pour le SEO« .
Avant de plonger corps et âme dans le monde des « nettoyeurs », veuillez notez 2 choses : Premièrement, on peut arriver au même résultat avec un M16 et un AK47 ! Comprenez qu’il existe d’autres méthodes que celles que je vais vous présenter ici. Sachez aussi que vous n’aurez pas toujours besoin de TOUT faire, à vous donc de picorer cet article au besoin comme un corbeau mange un cadavre ambulant…
Sommaire
- Avant-propos : data et zombies
- Importer les données
- Gérer les valeurs manquantes (NA)
- Enlever les caractères spéciaux dans les variables numériques
- Transformer une variable catégorielle en Factor
- Encoder une variable catégorielle avec le One Hot Encoder
- Transformer une variable factor en variable numérique
- Mettre les variables à l’échelle
- Retirer les outliers
Avant-propos : data et zombies
S’il avait pris le temps de se poser dans un coin et de sortir le Macbook Pro rangé à côté de son étui à fusil d’assaut automatique pour lancer R Studio, celui qui se dit « plus fort qu’une muraille » aurait probablement pu éviter de se faire croquer par un zombie et ainsi de mourir pour la 14ème fois.

Comment ?
En utilisant ce qu’il a appris dans ses cours de machine learning pour créer un modèle de prédiction, évidemment. Pour re-commencer la partie sur de bonnes bases voici le conseil que je lui prodiguerais :
– Nikolaï, il te faut créer un jeu de données pour entrainer le modèle
– Que mettre dans mon jeu de données, ô Grand Rémi qui a déjà atteint la manche 44 à Kino der Toten ?
– Николай Белинский, le plus d’infos possible sur chaque zombie rencontré tu dois récupérer : âge estimé, poids estimé, taille estimée, nombre de membres restants, sexe, lieu de rencontre, armes, couleur des yeux, etc… et surtout s’il a tué quelqu’un (tu noteras 1 pour oui et 0 pour non). Cette variable (« Tué quelqu’un ») sera notre variable à prédire. Nous allons entrainer notre modèle à détecter ce qui rend le zombie particulièrement menaçant et à chaque fois que tu rencontreras un nouveau zombie, tu seras capable de prédire le risque qu’il te tue ou non.
– ♫ On boit de la Vodka ce soir ♫ !
Compte tenu des conditions dans lesquelles les données vont être récupérées par Nikolaï (attaque de zombies), le dataset comportera probablement quelques soucis : erreur encodage. cellules vides, données de grandeur différentes, etc.
Le « dataset imparfait » est monnaie courante dans la plupart (la totalité ?) des projets data science, et il n y a vraiment pas besoin de travailler sur des prédictions d’attaques de zombies pour s’en rendre compte.
Une fois le « dataset » constitué, une phase de « data pre-processing » s’impose donc systématiquement. Cette préparation des données est indispensable pour tirer le meilleur des algorithmes de machine learning.
Importer les données
#Ouvrir le dataset dataset <- read.csv('my_dataset.csv',na.strings=c("")) #Connaitre le nombre de valeurs différentes dans chaque colonnes sapply(dataset, function(x) length(unique(x)))
Nous avons ici utilisé le paramètre na.strings qui nous permet de transformer les valeurs manquantes en NA (pour « Not Available »). Cela sera très utile pour la suite.
Gérer les valeurs manquantes (NA)
La plupart des « vrais » datasets que vous serez amené à utiliser comportent des cellules vides, des données manquantes ou corrompues et c’est précisément de ces données dont nous allons nous occuper maintenant.
Commençons par regarder le volume de données manquantes. Pour cela nous allons utiliser la fonction sapply qui permet d’appliquer la fonction sum() à chaque colonne du dataset.
#Compter le nombre de valeurs manquantes dans chacune des colonnes sapply(dataset,function(x) sum(is.na(x))) #Compter le nombre de NA dans une colonne en particulier sum(is.na(dataset$colonne)) Afficher les lignes dont la valeur dans la colonne "colonne" est NA dataset[is.na(dataset$colonne),]
Voici une astuce pour obtenir une visualisation de la proportion de valeurs manquantes de chaque colonne.
Nous utilisons le package R « Amelia ».
#Afficher un graph avec les valeurs manquantes vs les valeurs observées
library(Amelia)
missmap(dataset, main = "Missing values vs observed")

Passons maintenant à la gestion des données manquantes (à la main !).
Vous avez repéré qu’une colonne avait un taux élevé de valeurs manquantes ? Voici 2 options possibles pour y faire face :
#Option 1. Supprimer la colonne de votre dataset dataset$Colonne <- NULL #Option 2. Supprimer les lignes dont la valeur de cette colonne est NA dataset_2 <- subset(dataset, !is.na(dataset$colonne))
Vous avez repéré qu'une colonne avait quelques valeurs manquantes mais vous souhaitez l'utiliser quand même ?
L'une des solutions parmi les plus utilisées est de remplacer les valeurs vides par la moyenne ou la médiane de la colonne.
#Remplacer les valeurs manquantes par la moyenne de la colonne dataset$Colonne[is.na(dataset$Colonne)] <- mean(dataset$Colonne,na.rm=T) #Remplacer les valeurs manquantes par la médiane de la colonne dataset$Colonne[is.na(dataset$Colonne)] <- median(dataset$Colonne,na.rm=T) #Méthode plus fine : remplacer les valeurs manquantes par la médiane des lignes similaires dataset_filtered <- filter(dataset, dataset$classe==3 & dataset$embarquement=="Southampton") my_median <- median(dataset_filtered$prix,na.rm = T) full[is.na(dataset$prix) & dataset$classe==3 & dataset$embarquement=="Southampton" ,"prix"] <- my_median
Cette dernière méthode est celle que j'utilise le plus. C'est celle que j'ai par exemple utilisé pour remplacer le valeur manquante dans la colonne "prix" (Fare) sur la ligne du passager 1044 du dataset titanic, un exemple d'exercice de machine learning bien connu du site Kaggle que je vous invite à tester.
Enlever les caractères spéciaux dans les variables numériques
De nombreux jeux de données sur lesquels vous serez amenés à travailler peuvent comporter des variables avec des caractères spéciaux. C'est souvent le cas sur des colonnes de données financières (salaires, chiffre d'affaire, etc). L'intérêt est d'enlever tous les caractères spéciaux pour faciliter les calculs sur ces données.
Pour cela nous utilisons la fonction gsub() qui permet de remplacer des caractères par d'autres.
#Passer de $8,684 à 8684
gsub(",","",dataset$colonne)
gsub("\\$","",dataset$colonne)
Encoder une variable catégorielle en Factor
Si votre dataset comporte des variables catégorielles, elles doivent être encodées en factor.
#Vérifier qu'une variable catégorielle est encodée en Factor is.factor(dataset$Colonne) #Si la réponse est FALSE, il faut l'encoder vous-même : dataset$Colonne <- factor(dataset$Colonne, levels = c(0, 1)) #Encoder plusieurs variables en factor d'un coup factor_vars <- c('colonneA','colonneB','colonneC','colonneD') dataset[factor_vars] <- lapply(dataset[factor_vars], function(x) as.factor(x))
Encoder une variable catégorielle avec le One Hot Encoder
Le One hot encoding est une représentation binaire d'une variable catégorielle.
Imaginez par exemple que votre dataset comporte une variable (= une colonne) $Gender avec pour valeur "Men" ou "Female".
Le one hot encoding va transformer cette colonne en plusieurs colonnes correspondant chacune à l'un des 2 genres pré-cités, et ayant pour valeur des 0 et des 1.
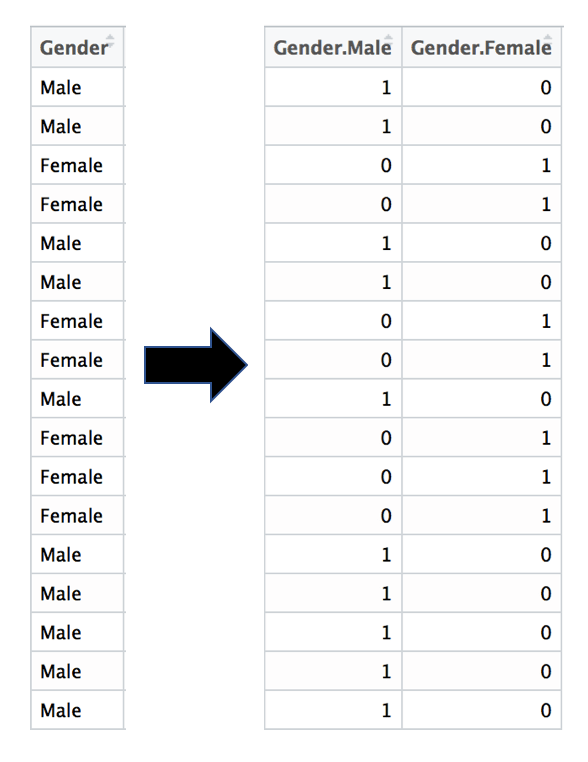
Voici le code pour faire du one hot encoding avec R :
#On crée un nouvelle colonne pour chaque valeur de la variable catégorielle for(unique_value in unique(dataset$Gender)){ dataset[paste("Gender", unique_value, sep = ".")] <- ifelse(dataset$Gender == unique_value, 1, 0) } #Ne pas oublier de supprimer une colonne générée par le One Hot Encoding dataset$Gender.Male <- NULL
Transformer une variable factor en variable numérique
Ici il y a un piège. Le premier réflex serait d'utiliser la fonction as.numeric() mais le résultat risque de compromettre votre jeu de données...
En effet, ce piège s'appelle le "Factor Variable Trap" (FVT) et voici la méthode pour le contourner avec la fonction unfactor() du package varhandle :
#Installez et chargez le package varhandle
library(varhandle)
dataset$variable <- unfactor(dataset$variable)
Features scaling
Avec le "features scaling" (= mise à l'échelle des variables) nous allons mettre les différentes variables sur le même ordre de grandeur pour améliorer les performances du modèle.
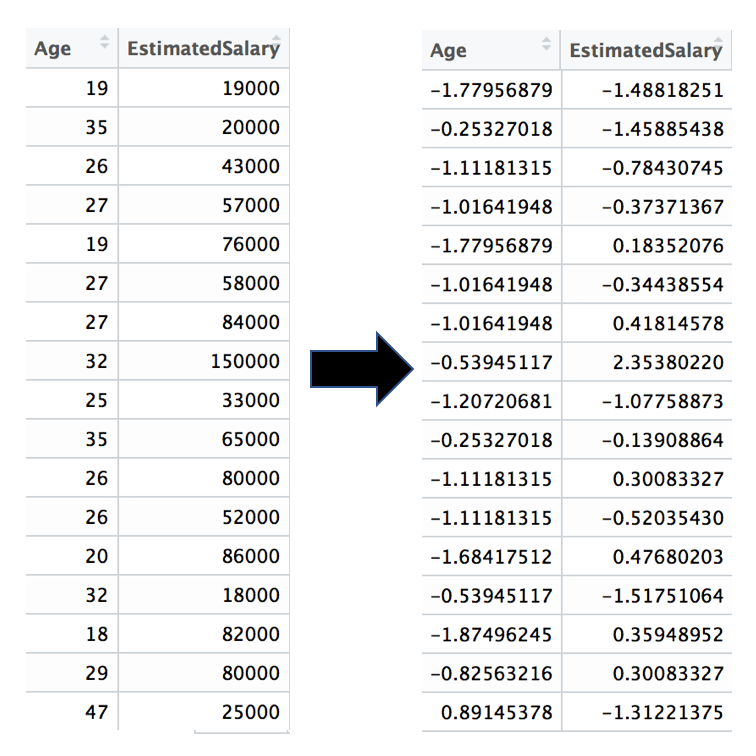
#Mettre les colonnes 1 et 2 à la même échelle
dataset[,1:2] = scale(dataset[,1:2])
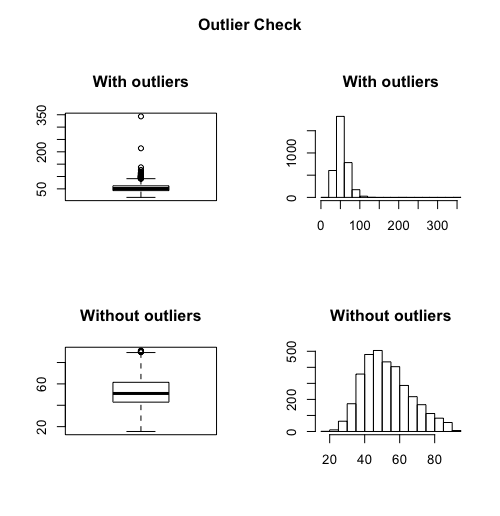
Détecter et supprimer les outliers
Un "outlier" (ou valeur aberrante) est une observation éloignée de la plupart des autres observations. La plupart du temps, la présence d'outlier dans un jeu de données est du à une erreur. Vous trouverez ici une méthode basée sur l'approche de l'intervalle interquartile (Tukey) pour identifier, afficher et supprimer les outliers d'un jeu de données.
Cet article évolue régulièrement !
J'espère que ce nouvel article sur R vous a plu ! Encore une fois j'insiste sur le fait que ce n'est pas nécessairement une recette à suivre mais plus une liste d'actions possibles pour préparer vos jeux de données.
Je mettrai l'article à jour de temps en temps avec de nouveaux scripts R pour le data pre-processing. Pour être au courant des prochaines mise à jour, n'hésitez pas à me suivre sur Twitter !
Bonjour j’ai lu votre article et ça m’a beaucoup aidé dans le traitement de mes données. Au fait, je voudrais savoir comment manipuler les données manquantes de types chaines de caractères c’est à dire comme dans le cas des données manquantes de types numériques cités ci dessus dans votre article.
Un article très riche, merci à vous.
Bonjour,
Merci de votre générosité. Est-ce que je peux savoir si ‘my_dataset.csv’ que vous avez utilisé pour afficher un graph avec les valeurs manquantes, est une dataframe ou une matrice?
Merci par avance
Pour une fois je tombe sur un article clair et précis, merci beaucoup! vous me sauvez.