
« Tout le monde le sait, les backlinks permettent de booster le positionnement d’une page sur Google ! »
En êtes-vous vraiment sûr ?
Vous l’avez probablement déjà remarqué, il n’est pas rare de voir des pages se positionner sans AUCUN backlink. Dans ce tuto, je vous propose une première approche pour analyser votre besoin en matière de lien sous la forme d’une analyse exploratoire de la SERP.
Prérequis
Nous allons ici utiliser le langage R et le logiciel R Studio pour faire tourner notre script.
Vous aurez également besoin d’une clé d’API Majestic, qui nous servira à automatiser la récupération de données de netlinking.
Si c’est le premier outil que vous développez avec R, aucune crainte, je vais ici vous expliquer une méthode simplifiée et nous construirons l’outil pas à pas.
Qu’allons nous faire concrètement ?
Nous allons créer un outil de pre-audit du netlinking qui fera 3 opérations :
- Récupérer le Top 100 des URL positionnées sur un mot-clés en utilisant le scraping
- Récupérer automatiquement plus de 140 variables de netlinking (CF, TF, Root Domain, etc) pour chaque URL, grâce à l’API de Majestic et au package R majesticR
- Analyser les corrélations entre la position des URL sur Google et leurs données Majestic
 Notez que si vous souhaitez aller plus loin
Notez que si vous souhaitez aller plus loinune méthode d’analyse multivariée, qui prend en compte le netlinking ainsi que les autres critères SEO (contenu, vitesse, etc), est enseignée dans le module dédié au machine learning de la formation Data Science SEO (Labs on Mars). Vous y découvrirez notamment comment construire une fonction de prédiction des rankings sur Google.
Prêt à analyser la SERP ? Alors GO !
1. Installer les packages R
Le code suivant va vérifier dans votre librairie si vous disposez déjà ou non des packages, et ne les installer que si vous ne les avez pas (Un bout de code à garder sous le coude !).
list.of.packages <- c("stringr", "httr","XML", "dplyr", "majesticR","Hmisc","corrplot","PerformanceAnalytics")
new.packages <- list.of.packages[!(list.of.packages %in% installed.packages()[,"Package"])]
if(length(new.packages)) install.packages(new.packages)
library(stringr)
library(httr)
library(XML)
library(dplyr)
library(majesticR)
library(Hmisc)
library(corrplot)
library(PerformanceAnalytics)
2. Récupérer le Top 100 des urls positionnées sur Google
On commence par créer notre scraper de SERP que nous appelerons get_google_serp_urls(). C’est une fonction qui va construire l’URL de la SERP à partir d’un mot-clé, en récupérer le contenu, puis en extraire les URL.
La fonction prend ici 5 paramètres :
- querie : le mot-clé dont on veut étudier la SERP
- number_of_results : le nombre de résultats que l’on veut récupérer (10, 100, etc)
- country_code : Le pays de la SERP (voir la liste des country code sur Wikipedia)
- language_code : La langue de la SERP (voir la liste sur Wikipédia)
- user_agent : le user agent avec lequel vous souhaitez faire la requête
Copiez-coller le code suivant dans un script R et exécutez-le pour installer les packages nécessaires et créer la fonction get_google_serp_urls()
#Create the R function to scrap the SERP
get_google_serp_urls <- function(querie, number_of_results, country_code, language_code, user_agent){
serp_url <- paste0("https://www.google.com/search?q=",querie,"&num=",number_of_results,"&cr=country",country_code,"&lr=lang_",language_code)
serp_url <- str_replace_all(serp_url,"\\s+","+")
serp_url <- as.character(serp_url)
request <- GET(serp_url, user_agent(user_agent))
doc <- htmlParse(request, encoding = "UTF-8")
doc <- htmlParse(request, asText = TRUE, encoding = "UTF-8")
urls_df <- data.frame(url = xpathSApply(doc, '//*[@class="r"]/a', xmlGetAttr, 'href'))
urls_df <- urls_df %>% mutate(position = row_number()) #dplyr
return(urls_df)
}
Voici un exemple de test de la fonction get_google_serp_urls(). Essayez-le pour récupérer votre Top 100 Google :
#Set the 5 parameters querie <- "deep learning" number_of_results <- 100 country_code <- "FR" language_code <- "fr" user_agent <- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" #Let's try the scraper my_url_dataset <- get_google_serp_urls(querie, number_of_results, country_code, language_code, user_agent)
Nous avons maintenant un dataset (my_url_dataset) qui contient les 100 premières URL positionnées sur la requête « deep learning ».
NB : Si pour une raison ou une autre vous souhaitez éviter de scraper vous-même la page de résultats de votre moteur de recherche préféré, notez que SEMrush propose également une fonction de récupération des URL de la SERP. J’ai intégré cette fonctionnalité dans SEMrushR, le package R que j’ai créé pour utiliser l’API de SEMrush pour utiliser l’API de SEMrush.
Passons à la récupération les data Majestic pour chacune de ces URL.
3. Récupérer les données de netlinking avec majesticR (API)
Vous l’avez peut-être vu passer sur mon compte Twitter, j’ai commencé à travailler sur majesticR, un package R pour se connecter facilement à l’API de Majestic et récupérer des données. C’est aujourd’hui un package R officiel (#OFFISHAL !) publié sur CRAN R, le site de référence des utilisateurs de R.
Pour la suite du tuto, j’ai utilisé la fonction majestic_all() de mon package majesticR qui permet de récupérer, pour une URL en particulier, les données Majestic de l’URL et du root domain (CF, TF, External backlinks, etc…). Afin que la récupération de données se fasse automatiquement sur toutes les URL de la liste que nous avons créé plus haut avec notre scraper (my_url_dataset), j’ai intégré la fonction majestic_all() dans une boucle.
Exécutez le script suivant en remplaçant les XXX par votre clé d’API Majestic, et profitez de la vie, vous venez de créer un robot qui récupère les data à votre place :
#Get Majestic URL and Root Domain data for Google Top 100
api_Key <- "XXXXXXXXXXXXXXXXXXXXXXXXXXX"
majestic_out <- data.frame(matrix(nrow=0, ncol=142))
for (i in 1:nrow(my_url_dataset)) {
majestic_doing <- majestic_all(my_url_dataset[i, "url"], api_Key)
majestic_out <- rbind(majestic_out, majestic_doing)
}
Bravo ! Vous venez de récupérer l’intégralité des data de netlinking du top 100 Google sur la requête « deep learning » et le tout a été stocké dans un dataset qui s’appelle « majestic_out ». Nous allons pouvoir analyser tout ça !
4. Préparer les données
Avant de passer à l’analyse des correlations entre la position et les différentes variables de netlinking que nous avons récupéré, une rapide étape de préparation des données s’impose. Nous allons ici ajouter 3 nouvelles colonnes (dont nous nous servirons dans la suite de ce tuto), puis créer un nouveau dataset qui contiendra exclusivement les colonnes que nous analyserons.
#Create the position variable
majestic_out <- merge(majestic_out, my_url_dataset,
by.x=c("Item"),
by.y=c("url")) #NEW
colnames(majestic_out)[143] <- "position"
majestic_out <- majestic_out[order(majestic_out$position),]
#Keep only some variables
myvars <- c("position","ExtBackLinks","RefDomains","RefIPs",
"CitationFlow","TrustFlow",
"DOMAIN_ExtBackLinks","DOMAIN_RefDomains","DOMAIN_RefIPs",
"DOMAIN_CitationFlow","DOMAIN_TrustFlow")
subset_majestic_out <- majestic_out[myvars]
#Create 3 new columns to help us find correlations
#majestic_out$isTop3 <- 1
#majestic_out$isTop3[majestic_out$position>3] <- 0
#majestic_out$isTop5 <- 1
#majestic_out$isTop5[majestic_out$position>5] <- 0
#majestic_out$isTop10 <- 1
#majestic_out$isTop10[majestic_out$position>10] <- 0
Ce que vous venez de faire est super cool ! Soyez en fier.
La récupération et la préparation des données sont des étapes (souvent adorées des data scientists) essentielles à tout projet de data science. L’étape suivante est l’analyse exploratoire des données afin d’y trouver des choses intéressantes…
5. Analyser les corrélations entre netlinking et position
Commençons par de simples tests de corrélations entre 2 variables en testant les correlations de Pearson and Spearman :
#Correlation between 2 continous variables cor(subset_majestic_out$position,subset_majestic_out$ExtBackLinks, method="pearson", use = "complete.obs") #[1] 0.02334821 cor(subset_majestic_out$position,subset_majestic_out$ExtBackLinks, method="spearman", use = "complete.obs") #[1] -0.3977484 cor(subset_majestic_out$position,subset_majestic_out$RefDomains, method="pearson", use = "complete.obs") #[1] -0.3045941 cor(subset_majestic_out$position,subset_majestic_out$RefDomains, method="spearman", use = "complete.obs") #[1] -0.3963901
Pour rappel, voici comment s’apprécient les valeurs que vous venez de retourner (les coefficients de corrélation) :

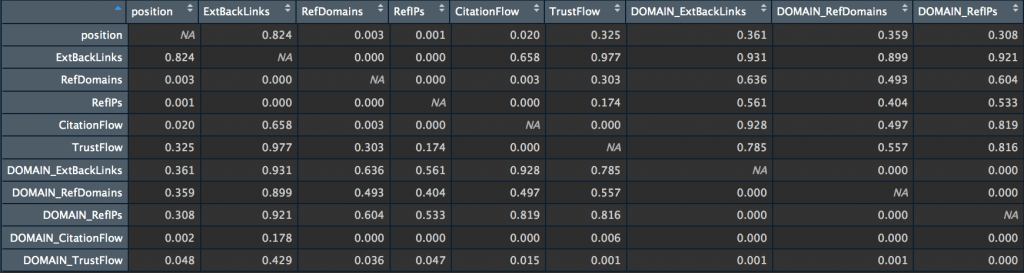
Si vous voulez évaluer la dépendance entre plusieurs variables en même temps, je vous conseille de créer une matrice de corrélations qui contient les coefficients de corrélation (ils servent à mesurer la force de la relation entre 2 variables), ainsi qu’une matrice avec la p-value.
La p-value permet en de mesurer la qualité des corrélations. Elle répond à la question suivante : s’il n’y a vraiment pas de corrélation entre X et Y dans l’ensemble, quelle est la probabilité que l’échantillonnage aléatoire produise un coefficient de corrélation aussi éloigné de zéro (ou plus) que celui observé dans cette expérience ?
 Pour en savoir plus sur la p-value (ou p-valeur), je vous conseille cette excellente vidéo de La statistique expliquée à mon chat.
Pour en savoir plus sur la p-value (ou p-valeur), je vous conseille cette excellente vidéo de La statistique expliquée à mon chat.
Revenons à nos matrices…
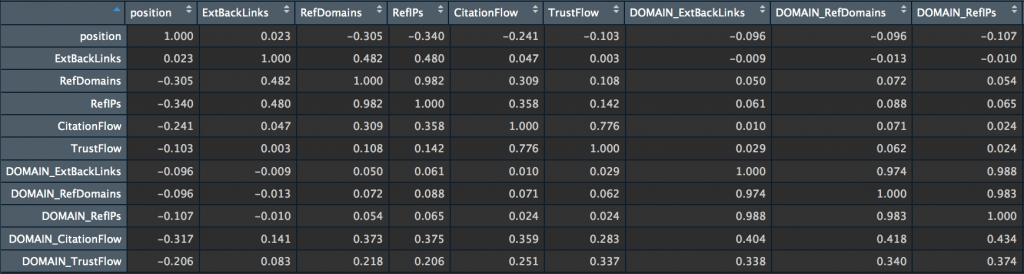
my_big_matrix <- rcorr(as.matrix(subset_majestic_out)) my_big_matrix # Extract the correlation coefficients correlation_matrix <- round(my_big_matrix$r,2) # Extract p-values pvalue_matrix <- round(my_big_matrix$P,2)
Terminons avec un peu de visualisation.
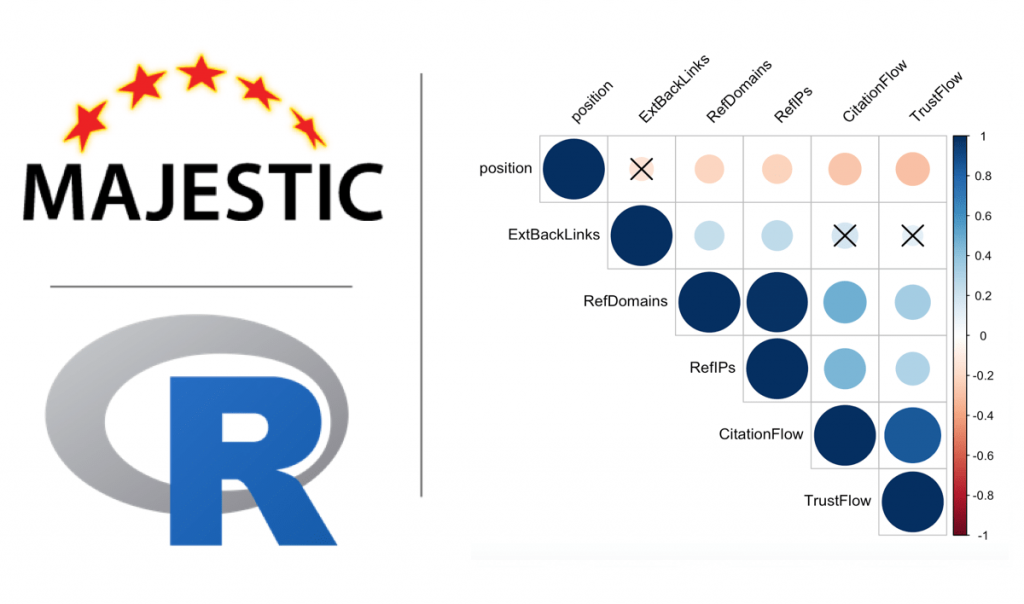
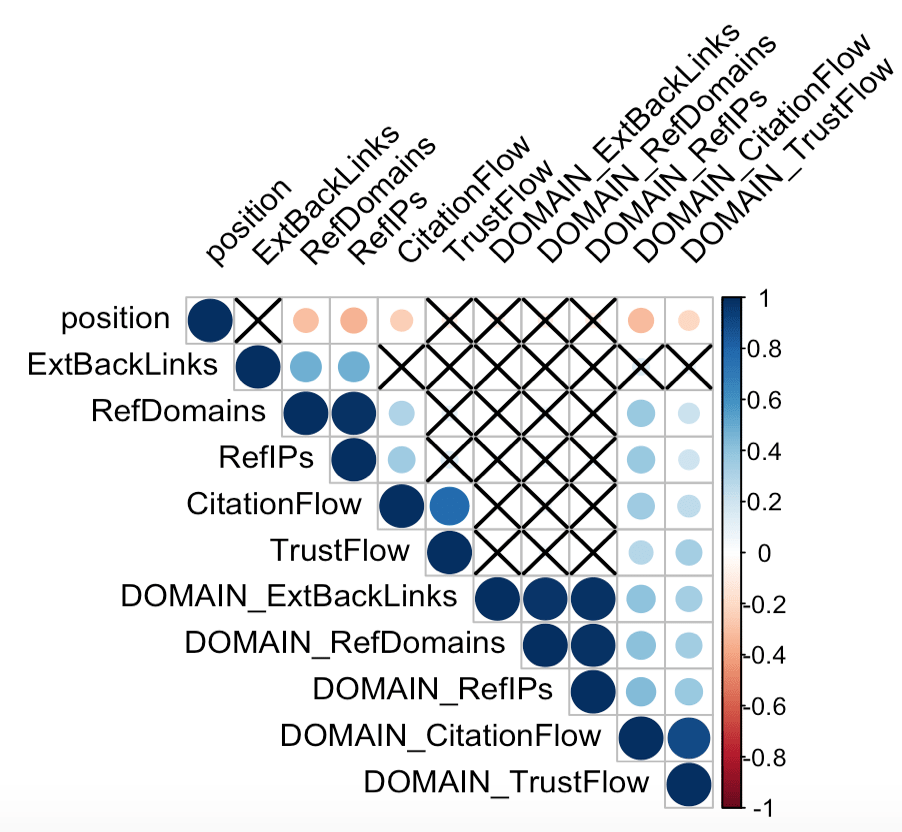
Nous allons créer un correlogram, une visualisation de la matrice de corrélation. D’un coup d’oeil le correlogram permet de voir l’intensité de la corrélation (la taille des cercle) et leur sens : les corrélations positives sont en bleu et les négatives en rouge. Les croix représentent les corrélations non significatives d’après leur p-value. J’ai moi-même spécifié le niveau de significativité à 0,05 (sig.level = 0.05).
corrplot(correlation_matrix, type="upper",
p.mat = pvalue_matrix, sig.level = 0.05, insig = "pch",
tl.col = "black", tl.srt = 45)
Enfin, la vue qui rassemble tout.
chart.Correlation(subset_majestic_out, histogram=TRUE, pch=19)
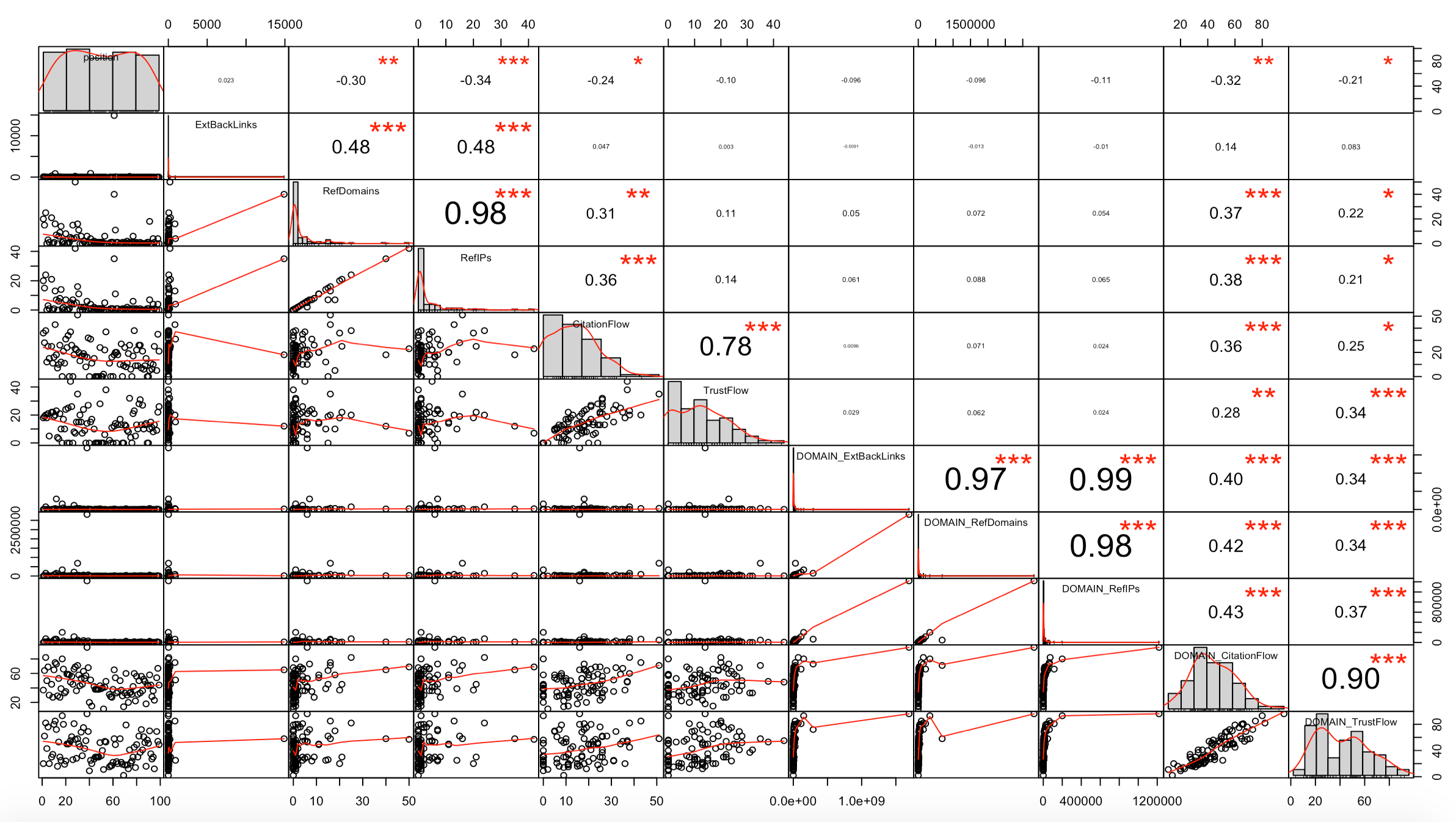
Cette vue peut faire peur de prime abord mais tout s’éclaire quand on sait où regarder !
On y voit :
- La valeur du coefficient de corrélation dans le « triangle » haut
- Une visualisation de type scatter plot dans le « triangle » bas, avec une ligne qui parcourt les points et donne le sens de la corrélation
- La distribution de chaque variable dans la diagonale (cellules avec le nom des variables)
- Le niveau de significativité (la p-value) de chaque corrélation au travers des symboles *** (p-value très proche de 0), ** (0.001), * (0.05), . (0.1) et espace vide (1)
6. Interprétation des analyses + La suite
Les coefficients de corrélation entre la positions des pages et les 10 variables de netlinking vues par Majestic (ExtBacklinks, RefDomains, RefIPs, CitationFlow, TrustFlow, pour l’URL et le root domain) sont ici assez faibles.
L’hypothèse qui ressort de cette première analyse est cependant que les RefDomains, RefIPs et DOMAIN_CitationFlow semblent avoir une certaine influence sur la position pour la requête « deep learning » sur Google FR.
Il s’agit ici d’une première approche pour essayer de tirer profit de la data à notre disposition. Il faut maintenant aller plus loin pour approfondir l’analyse :
- Utiliser des variables categorielles (Top3, Top5 et Top10) pour analyser les corrélations
- Ajouter d’autres variables correspondant aux différents critères de positionnements (temps de chargement, nombre de liens internes, taille des contenus, score sémantiques, etc etc etc…)
- Travailler avec plus d’observations (data augmentation)
- Faire une analyse multivariée en utilisant une approche machine learning afin d’être au plus proche du comportement du moteur de recherche. L’intérêt sera de prendre en compte les interactions entre les différentes variables. En d’autres termes, Si la variables TrustFlow semble ici avoir peu d’influence sur la position, il serait pourtant erroné de conclure qu’elle est inutile pour effectuer des prédictions car les corrélations entre le TrustFlow, la vitesse de chargement de la page et la position pourraient rendre le TrustFlow utile. C’est ce type de corrélation complexe et non-intuitive qu’un modèle de machine learning est capable d’apprendre.
J’espère que ce nouveau tuto vous a plu ! N’hésitez pas à me dire en commentaire si la suite de l’analyse vous intéresse !
Pour recevoir d’autres scripts R, abonnez-vous à ma newsletter et suivez-moi sur Twitter.
J’ai suivi tout le tuto et j’ai des visualisations assez proches des tiennes sur le mot-clé que j’ai testé sauf que j’ai eu un coef de corrélation à 0,54 sur External Backlinks VS top 10, c’est interessant pour avoir une première idée.
Une autre idée pour aller plus loin : ça pourrait peut être être pas mal d’essayer de faire l’exercice sur un groupe de mot-clés qui représentent une thématique.
Je suis intéressée pour lire la suite !
Merci Julie, content que tu aies testé les scripts ! Effectivement les coefficients de corrélation peuvent varier énormément d’une requête à l’autre. L’idée de faire l’analyse sur un groupe de mots-clés me semble très bonne.
– Sur un très grand volume de mots-clés (déjà testé sur 20 000) on peut s’en servir pour prioriser ses actions SEO à l’échelle d’un site ou d’une catégorie de site et ainsi arbitrer les investissements de façon macro (budget contenus vs budget liens vs budget webperfs par exemple) en étudiant les facteurs de ranking grâce au machine learning (cf formation DATA SEO LABS niveau 1). Cela permet également de créer une fonction de prédiction qui permet par exemple de tester des URL récemment mises en ligne afin de connaitre rapidement leurs lacunes pour viser le top 10 Google.
– Faire l’étude sur une thématique ne me parait pas indispensable. Je m’explique : par thématique, j’entends « les requêtes synonymes qui représentent une seule intention de recherche » (= les requêtes qui ne sont pas forcément proches d’un point de vue sémantique mais qui déclenchent l’affichage de la même SERP, des mêmes résultats). Si ces quelques requêtes déclenchent la même SERP, je pense que cela revient à étudier la SERP d’une seule de ces requêtes. Etudier la SERP de toutes ces requêtes permettrait de faire l’étude sur plus de données, mais les données seraient ainsi gonflée de façon artificielle. N’oublions pas que d’une requête à l’autre, même dans la même niche, les critères de ranking peuvent être trèèèès différents.
Ton article m’a décidé à écrire mes premières lignes en R ! J’appréhendais un peu mais en fait c’est super simple avec le code que tu donnes.
J’ai testé sur quelques mots-clés et j’ai trouvé des corrélations intéressantes qui me donnent de bonnes pistes pour ma stratégie SEO. Merci Rémi et sans doute à bientôt lors d’une de tes prochaines formations, ça m’a donné envie de creuser le sujet !
Merci Victoire ! Bravo pour tes premières lignes de R !!! Ce script est un début, je suis sûr que l’on peut encore améliorer la méthode… Je mettrais l’article à jour régulièrement au fur et à mesure des réflexions et idées.
A tester avec les metrics domain et non URL (ou à ajouter), cela serait sans doute plus parlant 🙂
Tu as raison, les métriques domain fournissent également de supers infos ! J’ai mis à jour mon package R majesticR afin de récupérer les données Majestic ROOT DOMAIN et URL en une seule fonction. Selon les requêtes on a des résultats hyper différents. J’ajoute ça à l’article !
Pourquoi tu passes par l’API, pour moi ca donne une certaine restriction au niveau utilisateur majestik (cf les compte à 39€ sans accès à l’API).
Par contre, tu pourrais faire la même chose en passant par le token majestik et donc te passer de l’api 😉
Hâte de voir la V 1.2
Ton moïse le geek 😉
Hello mon Moise le geek, je n’ai pas encore eu l’occasion d’utiliser la méthode avec token sans API, faudra que tu m’expliques ça à l’occasion ^^ ! Si tu as de la doc, ça peut sûrement intéresser d’autres personnes… La V1.2 arrive, je pense que je vais devoir ajouter un changelog à l’article LOL !
Peut-on réellement tirer des conclusion de cette analyse ? Je pense qu’il faudrait plus de données et étudier d’autres SERP afin d’avoir la corrélation par clusters de mots clés.
Hello Amine, je pense avoir répondu à cette question dans le 1er commentaire, dis-moi si ce n’est pas clair !
Excellent article comme souvent ici ! Hâte de lire la suite de l’analyse et en particulier l’utilisation d’autres données SEO comme les liens vers le domaine. Merci Rémi
Hello Paul, l’article est à jour et le script intègre maintenant les données root domain de Majestic SEO.