
Vous allez découvrir ici comment j’ai créé un scrapper en R pour récupérer des paroles de chansons d’Eminem et la façon dont je les ai étudiées grâce au text-mining, une méthode qui permet de transformer des textes en données.
La finalité est de mesurer les sentiments dominants dans chacun de ses albums et les mots les plus utilisés dans ses textes.
Nous sommes en 2000, j’ai dix ans et je viens de me prendre ma première claque musicale en regardant un clip à la télé : un extra-terrestre blond crache dans un hamburger, pose ses fesses sur la tête d’un chanteur de boys band et scande des « Please stand up, please stand up ». C’est le coup de foudre !

Quelques 17 années ont passé et l’album The Marshall Mather LP de Eminem fait toujours partie de mes madeleines de Proust. Je comprends beaucoup mieux l’anglais qu’à l’époque même si de nombreuses rimes m’échappent encore tant Eminem joue avec les mots, leur donne des sens multiples et à des débits parfois poussés (souvenez vous de sa performance sur le son Rap God : 6.6 mots PAR SECONDE).
Je partage ici ma méthodo pour récupérer et analyser les paroles, ainsi que les astuces apprises en chemin.
OSEF du code, je veux voir les résultats de l’étude
Si vous voulez zapper la partie technique et voir directement les résultats de mon étude sur Eminem, rendez-vous en bas d’article.
Récupération des paroles avec le Web Scrapping
La première chose à faire quand on veut scrapper est de connaitre l’URL où se trouve la donnée qui nous intéresse. Ici la récupération de données se fera en 3 temps :
1. Récupérer les URL de chaque page album
2. Récupérer les URL des paroles de chaque album
3. Extraire le texte utile des pages paroles
J’ai utilisé le langage R (via le soft R Studio) dont je vous parlais dans mon article Utiliser R pour le SEO. N’hésitez pas à aller le relire pour avoir quelques bases en R.
Voici comment récupérer le code source d’une page artiste :
library(XML) #Pour la fonction htmlParse() library(httr) #Pour la fonction GET() artist <- "eminem" url_website <-"https://website.com" url_repo <- "/artists/" url_artist <- paste0(url_website,url_repo,artist) request <- GET(url_artist) doc <- htmlParse(request, asText = TRUE)
Un coup de xPath pour récupérer les liens dans le code source, puis un grep pour récupérer les liens qui contiennent /albums/ :
xpathSApply(doc, "//div/a", xmlGetAttr, 'href')
grep("albums", dataset, value = TRUE)
Il suffit ensuite de récupérer le dernier lien de la liste qui est un lien vers tous les albums (/artists/albums?for_artist_page=45&id=Eminem) et de recommencer le processus précédent : récupération du code source, xpath et grep.
Nous obtenons une liste des liens vers les pages albums de l’artiste.
J’ai ensuite créé une boucle avec for pour récupérer les URL de chacune des chansons de chaque page album de l’artiste. La boucle récupère le code source de l’URL album avec htmlParse, récupère les liens des chansons avec xPath, et ne garde que les liens qui contiennent « lyrics » grâce à la fonction grep(). Voici quelques éléments de la boucle :
doc <- htmlParse(request, asText = TRUE)
hrefs <- xpathSApply(doc, "//a", xmlGetAttr, 'href')
url_songs <- list(grep("lyrics", hrefs$liens, value = TRUE))
Une fois arrivé à cette étape, nous avons récupéré les liens de TOUTES les pages paroles de TOUTE la discographie d’Eminem. Pour mon étude, j’ai souhaité me focaliser sur ses albums studio et exclure ses mixtapes et side -projects, j’ai donc créé un filtre :
albums_to_keep <- c("Infinite",
"Slim shady lp",
"The marshall mathers lp",
"The eminem show",
"Encore",
"Relapse",
"Recovery",
"The marshall mathers lp2")
url_all_albums_artist_filter <- filter(url_all_albums_artist, liens %in% albums_to_keep)
Il est temps de préparer le dataset pour l’ultime scrap : la récupération des paroles. Pour cela, je vais créer une ligne par URL de parole grâce à aux fonctions strsplit(), rep() et sapply().
strsplit() divise la le contenu de c(« url 1 », « url 2 », « url 3 ») en une liste du type :
[1] « c(« url 1″ »
[2] « url 2 »
[3] « url 3 »)
url_all_albums_artist_filter$songs <- as.character(url_all_albums_artist_filter$songs) url_albums_songs <- strsplit(url_all_albums_artist_filter$songs, split = ",")
Pour créer le dataset final, nous gardons uniquement 2 colonnes : le nom de l’album et l’URL de la chanson à scraper.
url_albums_songs <- data.frame(Album = rep(url_all_albums_artist_filter$liens, sapply(url_albums_songs, length)), songs = unlist(url_albums_songs))
Avant de pouvoir passer à la boucle de récupération des paroles, une phase de préparation du dataset s’impose :
– supprimer les éléments parasites (guillemets, parenthèses, etc) pour ne garder que les URL
– supprimer les URL inutiles (credits-lyrics, annotated, tracklist, booklet)
– supprimer les doublons (quelques URL en http et https)
url_albums_songs$songs <- gsub(".*https","https",url_albums_songs$songs)
url_albums_songs$songs <- gsub(".*http:","https:",url_albums_songs$songs)
url_albums_songs$songs <- gsub("lyrics.*","lyrics",url_albums_songs$songs)
remove <- c("credits-lyrics","http://", "annotated", "tracklist", "booklet")
url_albums_songs <- url_albums_songs[!grepl(paste(remove, collapse="|"), url_albums_songs$songs),]
url_albums_songs <- url_albums_songs[!duplicated(url_albums_songs), ]
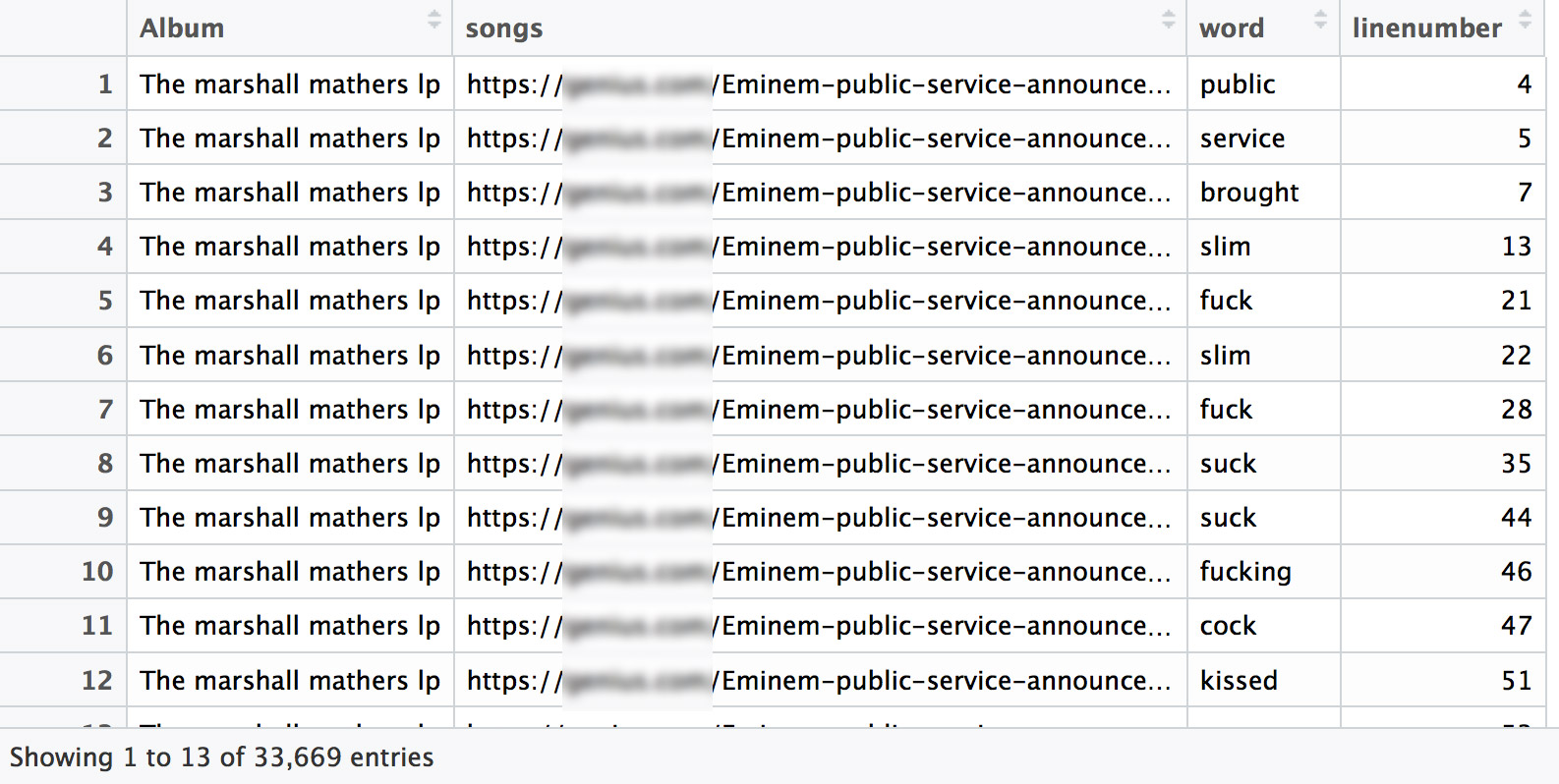
C’est parti pour la boucle finale ! On scrape les URL de paroles et on récupére le contenu texte utile. Le dataset final ressemble maintenant à ça :

Étude des paroles grâce au Text-mining
Comme vous pouvez le voir dans l’image ci-dessus, les paroles récupérées comportent leur lot de mots inutiles. Des termes comme [Intro], [Verse] [Produced by …] ou encore [Hook] pourraient perturber l’analyse car ils sont très présents dans le dataset. L’utilisation d’une expression régulière (regex) prend ici tout son sens pour supprimer tout ce qui est entre crochets.
J’ai aussi remarqué qu’il n y avait pas de saut de ligne entre les paroles. Les premiers mots et derniers mots de chaque ligne se retrouvent donc collés (againEminem, myselfsmoke, etc) ce qui est là aussi problématique pour l’analyse.
Pour fixer ces soucis, j’ai utilisé les lignes suivantes :
url_albums_songs$lyrics <- gsub('\\[.*?\\]', '', url_albums_songs$lyrics)
url_albums_songs$lyrics <- gsub('([[:upper:]])', ' \\1', url_albums_songs$lyrics)

L’analyse requiert aussi que le dataset soit disposé différemment. Plutôt que d’avoir tout le texte d’une chanson sur une seule ligne, il faut passer à une table avec un un mot par ligne.
Pour cela j’utilise le package R tidytext()
url_albums_songs_tidy <- url_albums_songs url_albums_songs_tidy$lyrics <- as.character(url_albums_songs_tidy$lyrics) url_albums_songs_tidy <- url_albums_songs_tidy %>% unnest_tokens(word, lyrics) url_albums_songs_tidy$linenumber <- NA nrowurl_albums_songs_tidy <- nrow(url_albums_songs_tidy) url_albums_songs_tidy$linenumber <- 1:nrow(url_albums_songs_tidy)
Les données sont prêtes, passons à l’analyse de sentiments.
Analyse de sentiments
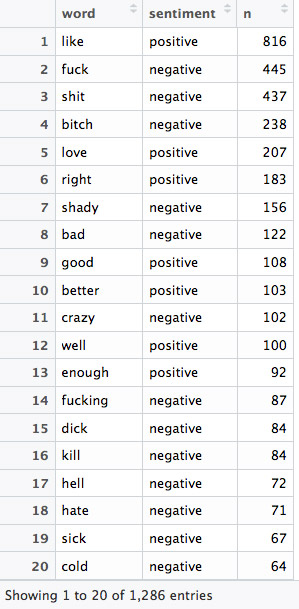
Pour cette analyse j’utilise le lexique bing qui catégorise les mots de façon binaire : positif vs négatif. Le lexique comporte 6 788 mots catégorisés.
L’idée est de comparer notre dataset de paroles au lexique bing, grâce à la fonction inner_join(). Les mots sont ensuite rangés par fréquence.
Notez qu’à cette étape de l’analyse il n’est pas nécessaire de supprimer les stop_words, car les mots étudiés sont seulement les mots en commun avec le lexique bing.
bing <- get_sentiments("bing")
bing_word_counts <- url_albums_songs_tidy %>%
inner_join(bing) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()
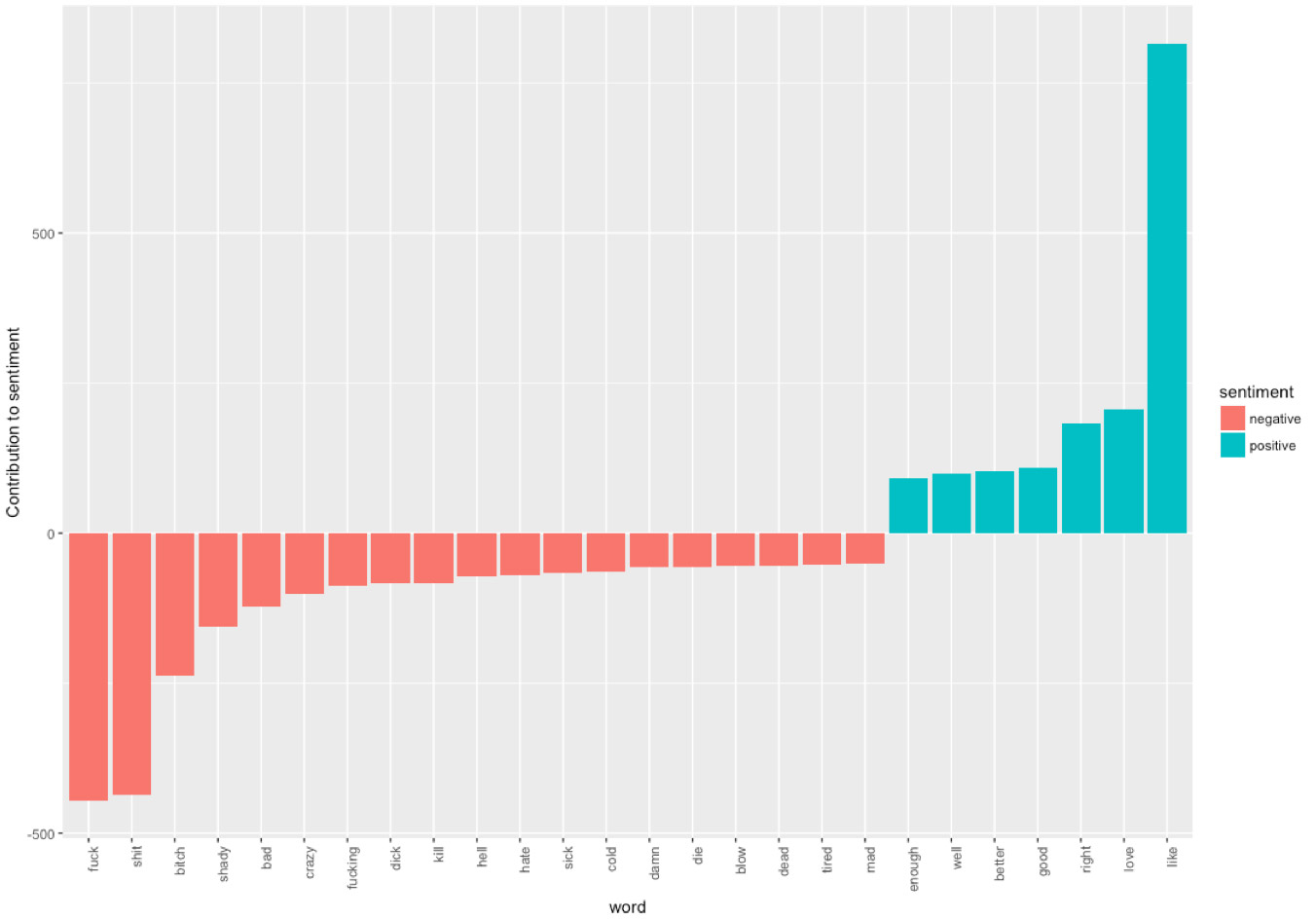
On peut ensuite afficher ces données sous forme d’histogramme avec la library ggplot2
library(ggplot2)
bing_word_counts %>%
filter(n > 30) %>%
mutate(n = ifelse(sentiment == "negative", -n, n)) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Contribution to sentiment")
Pour aller plus loin on crée un nuage de mots avec la librairie R wordcloud qui divise les mots selon qu’ils soient positifs ou négatifs.
library(reshape2)
library(wordcloud)
url_albums_songs_tidy %>%
inner_join(bing) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("#F8766D", "#00BFC4"),
max.words = 100)

Regardons maintenant l’évolution des sentiments au sein des albums.
Pour une meilleure lisibilité, je découpe le dataset de 114 553 lignes en 2444 sous-ensembles. Chaque sous-ensemble (index) est composé d’un regroupement de 50 mots. Chacun de ses sous-ensemble est ensuite comparé au lexique bing et obtient une note de sentiment.
Plus le sous-ensemble comporte de mots positifs et plus la note sera élevée, plus il comporte de mots négatifs et plus la note est basse.
library(tidyr) #pour la fonction spread janeaustensentiment <- url_albums_songs_tidy %>% inner_join(bing) %>% count(albums, index = linenumber %/% 50,sentiment) %>% spread(sentiment, n, fill = 0) %>% mutate(sentiment = positive - negative)
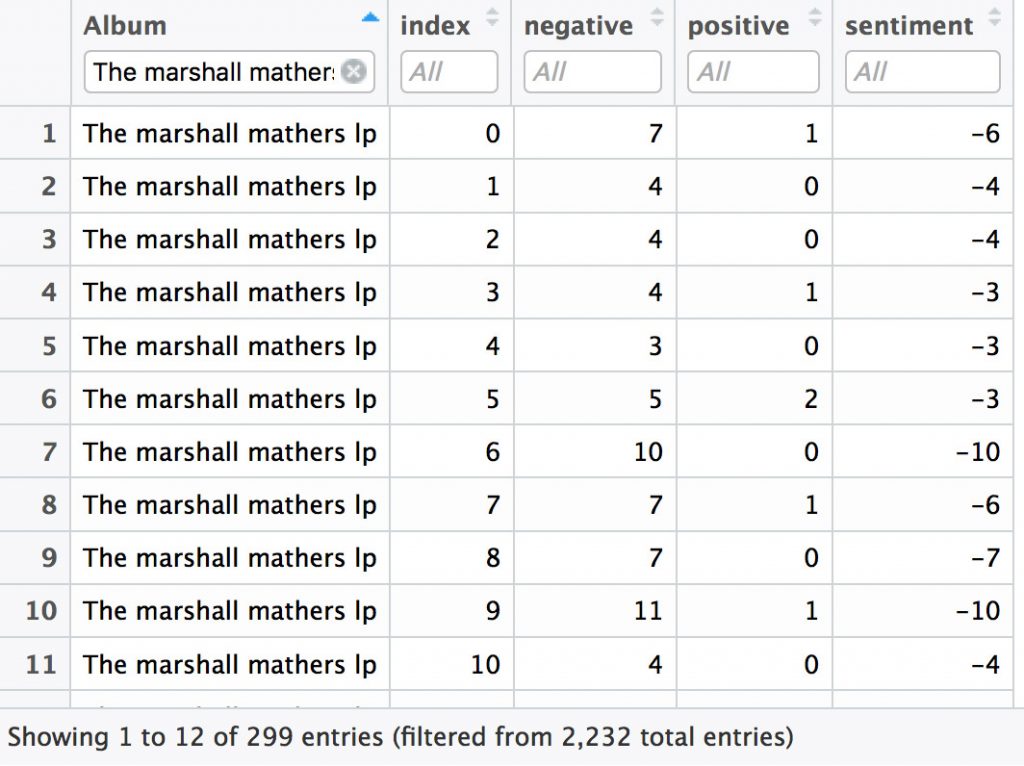
Un peu de data visualisation pour rendre le tout intelligible et nous obtenons une évolution des sentiments pour chacun des albums étudiés.
ggplot(janeaustensentiment, aes(index, sentiment, fill = albums)) + geom_bar(stat = "identity", show.legend = FALSE) + facet_wrap(~albums, ncol = 2, scales = "free_x")

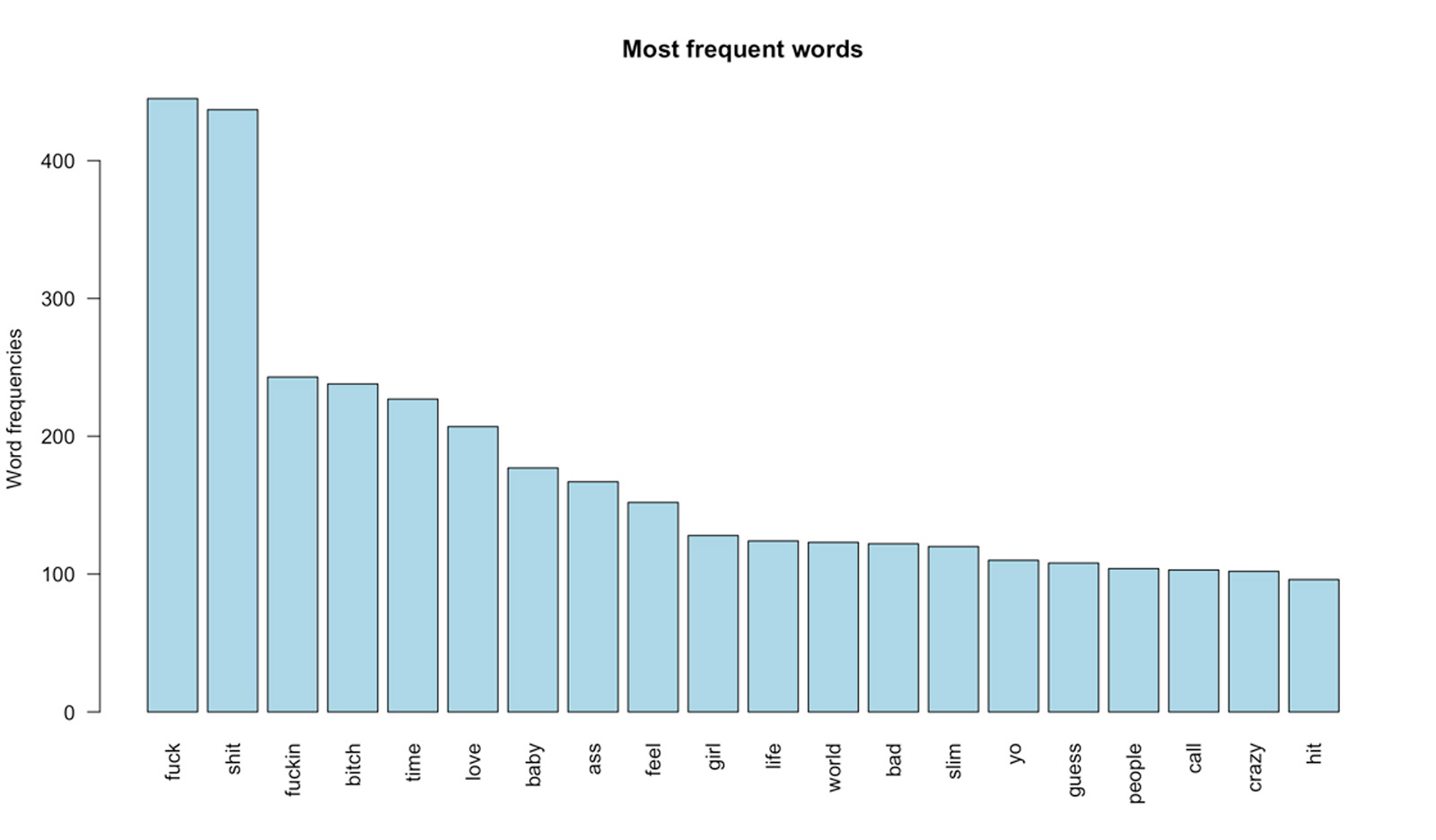
Fréquence de mots
Reprenons le dataset url_albums_songs_tidy (celui avec un mot par ligne qui comporte 114 553 lignes)
Il faut maintenant y supprimer les stopwords (les mots creux) car ils sont très présents et risquent de perturber l’analyse. Savoir qu’Eminem a utilisé 600 fois le terme « a » ou « an » ne ne aidera pas beaucoup… L’idée est de ne garder que les mots utiles.
Je récupère une liste de 1149 stopwords anglais déjà existante à laquelle j’ajoute ma liste custom pour améliorer le filtrage.
custom_stopwords <- c("i’m","i'ma","gonna","wanna", "gotta","he","ii", "da", "1","2","3","4","5","6","7","8","9","em","ah","ha","uh","ya","til")
url_albums_songs_tidy <- url_albums_songs_tidy[ !grepl(paste(custom_stopwords, collapse="|"), url_albums_songs_tidy$word),]
data("stop_words")
url_albums_songs_tidy <- url_albums_songs_tidy %>% anti_join(stop_words)
Il ne reste plus qu’à regrouper ces termes par fréquence et à les visualiser sous forme d’histogramme.
wordcount <- data.frame(url_albums_songs_tidy %>% count(word, sort = TRUE) )
barplot(wordcount[1:20,]$n, las = 2, names.arg = wordcount[1:20,]$word,
col ="lightblue", main ="Most frequent words",
ylab = "Word frequencies")
Résultats de l’étude des 8 albums studio d’Eminem

N’hésitez à me suggérer des artistes que vous aimez en commentaire ou directement sur Twitter, je publierai de temps en temps de nouvelles analyses de discographie.
J’ai déjà quelques idées d’amélioration de ce script, je vais continuer à l’améliorer au fil de l’eau 😉
Ma prochaine conférence à Paris
Je profite de cet article pour vous annoncer que je donnerai ma prochaine conférence à l’OVH Summit le 17 octobre, à Paris.

RDV à 16 h sur la scène principale ! Et d’ici là, je compte sur vous pour partager et liker cet article s’il vous a plu 😉
[NOUVEL ARTICLE] Eminem et ses 465 ‘fuck’ : Web scrapping et text mining (R) > https://t.co/WIXcKIQjO6 #DataScience #Eminem #rstats pic.twitter.com/yc8aRkRUG2
— Rémi Bacha (@Remibacha) 25 septembre 2017
Intéressante cette étude (ainsi que le petit tuto qui va avec)…
Par contre, je trouve que dans le cadre de l’analyse d’un rappeur, il aurait été intéressant de conserver le terme « I’m »… Ceci à fin de donner une idée de la dimension Egotrip
Merci pour ton retour, c’est une bonne idée ! Mais il faudrait aussi ajouter tous les termes relatifs à la première personne dans ce cas.
Voici le nombre d’apparitions pour chaque terme :
I : 4232
me : 1661
my : 1610
i’m : 1408
i’ma : 109
mine : 34
Très intéressante cette application de R ! 🙂
Une remarque toutefois sur la conclusion de ton étude : il semblerait que le lexique bing ne prenne pas en compte que le mot anglais « like » puisse avoir plusieurs significations, au delà du sens « aimer » / « apprécier ».
En effet, si on reprend au hasard manuellement quelques paroles, on s’aperçoit que « like » ne témoigne pas systématiquement d’un sentiment positif car le mot est parfois employé au sens « comme » :
– « Hit the earth like an asteroid »
– « We all fall down, like toy soldiers, bit by bit, torn apart »
– « I’m beginning to feel like a Rap God, Rap God »
– « Now I’m talking a man who literally saved my life, like fuck it »
etc..
En revanche, je pense que le mot « fuck » est relativement clair ^^
Merci Fred,
Dans l’infographie finale, j’ai choisi de montrer le diagramme avec les termes classés par sentiment et malgré la polysémie du terme « like », puisqu’il était dans le lexique Bing j’ai décidé de le garder.
Par contre dans l’analyse de fréquence, un peu plus haut dans l’article (voir « Fréquence de mots »), le terme a bien été supprimé car il était contenu dans la liste de stop_words.
Salut Rémi,
Intéressant cet article.
Est-ce que l’analyse des sentiments peut être biaisé par des formes de langages tels que l’ironie, le sarcasme ou l’humour ?
Voici un exemple avec le verbe hope (dans Stan) qui est utilisé dans un contexte négatif en premier et positif en second :
« I hope your conscience eats at you »
« I hope you get to read this letter »
Un autre exemple avec des termes de ton tableau : « I fucking love it » la phrase comporte un négatif et un positif mais est positive (et peut être négative si ironie).
Est-ce que les analyseurs de sentiments sont assez puissants pour englober un contexte ? Si non, en est on encore loin ?
Hello Vincent,
Merci pour ton retour,
oui, les formes de langage que tu mentionnes peuvent en effet compliquer l’analyse.
La difficulté est dans le fait que l’ironie reste, même pour un humain, parfois difficile à détecter.
Il y a des formes d’ironies « communes » et d’autres « nouvelles » et totalement subjectives, et ces dernière en particulier augmentent la difficulté.
Je t’invite à lire cette étude si le sujet t’intéresse : « A comparison between semi-supervised and supervised text mining techniques on detecting irony in greek political tweets » (trouvable sur Google)
Hello Rémi,
J’avais lu ton article lorsqu’il était sorti et aujourd’hui je suis arrivé sur un nouvel article qui m’a fait pensé au tien : http://colinfay.me/purrr-web-mining/
Ici, ce n’est pas un tutoriel complet comme celui que tu avais écrit, mais il y a des infos en plus, d’autres différentes et j’ai bien aimé l’approche, dont l’utilisation du package
{purrr}