
Il existe aujourd’hui de nombreuses façons de faire une analyse de logs mais chaque analyse requiert la plupart du temps une longue phase préparatoire : récupération des logs, regroupement, séparation des données en colonnes, nettoyage, etc. Ces traitements, plus ou moins complexe selon les cas, peuvent parfois refroidir, surtout quand ils sont faits à la mano…
Dans ce guide pratique, je vais vous montrer comment faire tout ça rapidement et exploiter les logs d’un hébergement web OVH grâce à Dataiku, un outil de Data Science.
Cet outil est une petite révolution dans le domaine du traitement de la donnée et vous allez vite comprendre pourquoi.
Ah… et j’oubliais…
Dataiku dispose d’une version gratuite qui a en plus l’avantage de s’installer sur votre machine afin que les données restent en local !!!!
Sommaire
- Partie 1 : Prise en main de Dataiku DSS pour l’analyse de logs
- Installer Dataiku DSS
- Connecter les logs OVH à Dataiku
- Vos premières analyses
- Partie 2 : Préparation des logs pour une analyse SEO
- Nettoyer les logs
- Filtrer les logs des bots (GoogleBot, BingBot, etc)
- Partie 3 : Analyse de logs avancée
- Status code rencontrés par les bots
- Fréquence de passage des bots par URL
- Comportements des bots sur les pages mobiles et AMP
- Croiser les logs avec les données d’un crawl Screaming Frog
- Trouver vos corrélations entre logs et données du crawl
PARTIE 1 : Votre première analyse de logs avec Dataiku
Installer Dataiku DSS
Commencez par l’installation de Dataiku DSS sur votre ordinateur : https://www.dataiku.com/dss/trynow/
Connecter vos logs OVH à Dataiku
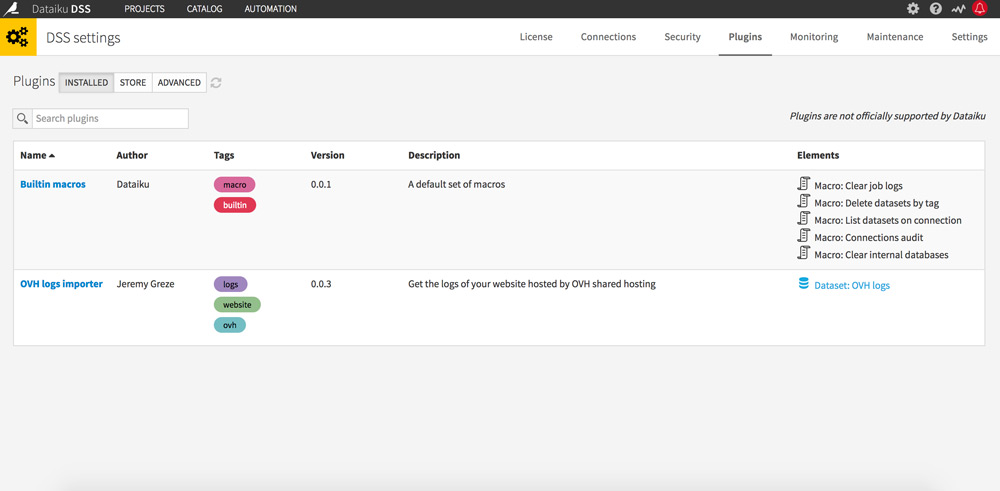
Rendez-vous dans l’administration (picto roue dentée en haut à droite), puis dans l’onglet Plugins.
Cherchez et installez le plugin OVH Logs Importer de Jérémy Grèze.
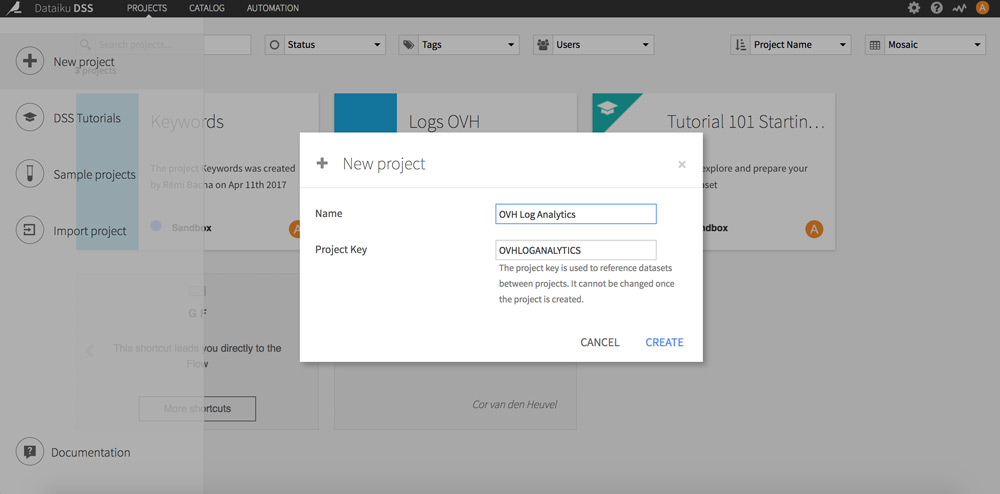
Retournez sur la page d’accueil et cliquez sur le + en haut à gauche. Choisissez « New Project ».
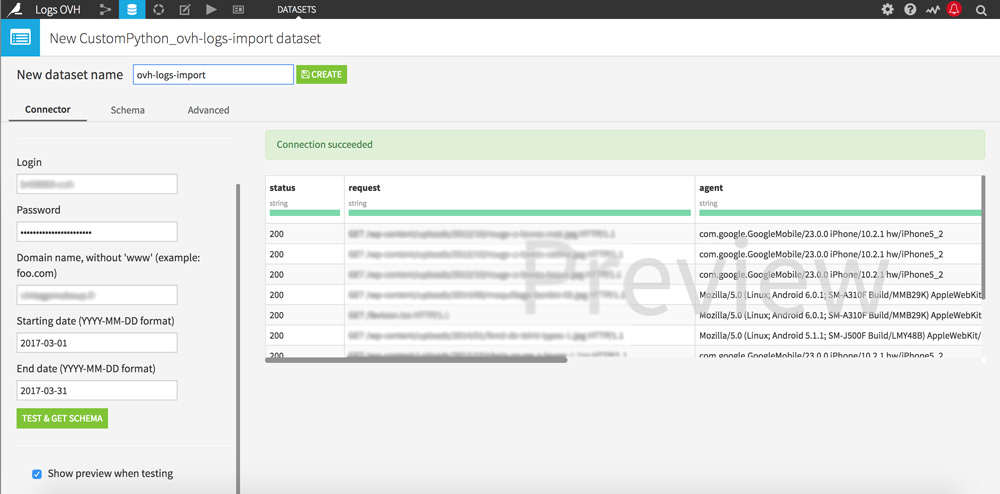
Cliquez sur le bouton « + Import your first dataset » et sélectionnez « OVH logs ».
Une nouvelle page s’affiche.
Remplissez les champs avec vos identifiants OVH, le nom de domaine que vous souhaitez étudier et la période d’analyse qui vous intéresse. Cliquez ensuite sur le bouton « Test & get Schema » pour démarrer la récupération des logs.
Quelle période étudier ?
Je vous conseille d’étudier au minimum les 30 derniers jours pour une analyse représentative. Elle vous permettra par exemple de repérer les pages ignorées par Google Bot.
L’analyse peut prendre quelques minutes selon la période sélectionnée.
Une fois la récupération terminée, un échantillon de vos logs apparait sur l’écran de droite, avec les infos correctement classées : magique ! Donnez un nom à votre dataset et cliquez sur le bouton « Create » en haut de l’écran.
Vous allez maintenant pouvoir commencer l’analyse des logs de votre site web : analyser le trafic, étudier les status codes rencontrés par les visiteurs/Bots, etc.
Nous allons commencer par quelques manipulations basiques afin que vous pussiez prendre Dataiku DSS en main rapidement.
Avant-propos : Dataiku DSS utilise un échantillon de 10 000 lignes afin que les traitements s’effectuent en direct. Vous pouvez agrandir l’échantillon selon les capacités de votre machine. Pour cela, cliquez sur 10 000 rows, sous Design Sample en haut à gauche.
Vos premières analyses
Sur votre dataset, cliquez sur le bouton LAB en haut à droite. Une popup s’ouvre, cliquez sur « NEW Prepare data and build models » pour créer votre analyse.
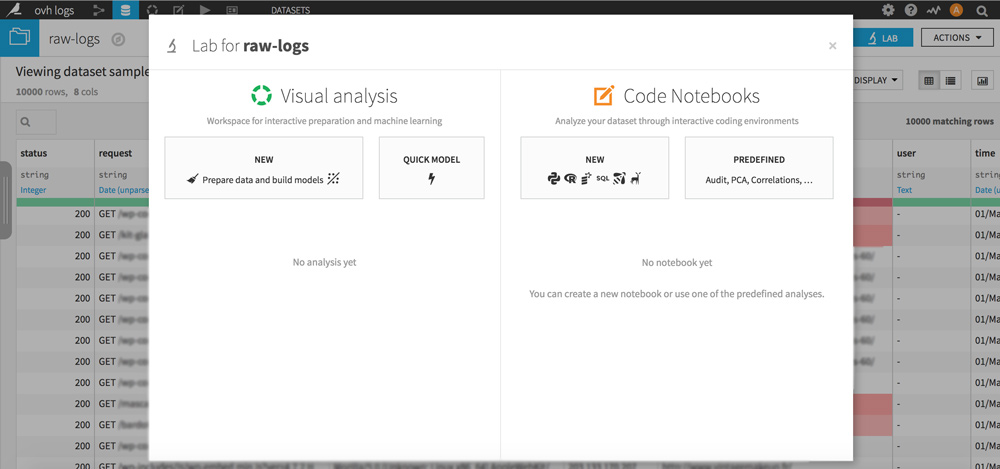
Cliquez sur le bouton vert + ADD A NEW STEP et choisissez la ou les librairie(s) qui vous intéressent.
Cette opération sera à reproduire à chaque fois qu’il sera question de création d’analyse dans ce guide.
Status code rencontrés par les visiteurs
Cliquez sur l’intitulé de colonne « status » puis sur « Analyse… ». Bravo vous venez de faire votre première analyse de logs !
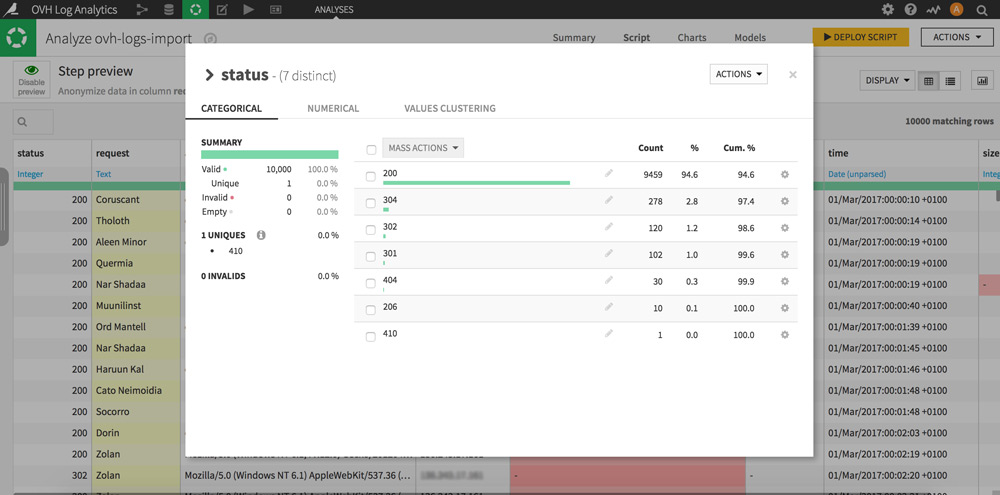
Certes très simpliste mais pour autant pas inintéressante : vous avez devant vous la répartition de tous les status codes réellement rencontrés par les visiteurs (humains et bots) de votre site. À vous de jouer pour améliorer conjointement l’expérience utilisateur et le parcours des bots.
Astuce : Un clic sur la roue dentée de chaque ligne vous permettra d’effectuer des traitements dans votre dataset. Par exemple n’afficher que les lignes qui contiennent le status code 404 afin de prioriser votre ménage.Geolocalisation des IP des visiteurs
Dataiku DSS propose différentes façons d’enrichir vos datasets via des API externes et des bases de données.
Nous allons ici enrichir les adresses IP d’infos géographiques : pays, régions, villes.
Cliquez sur l’intitulé de la colonne « host », puis sur « Resolve GeoIP ». 7 nouvelles colonnes apparaissent.
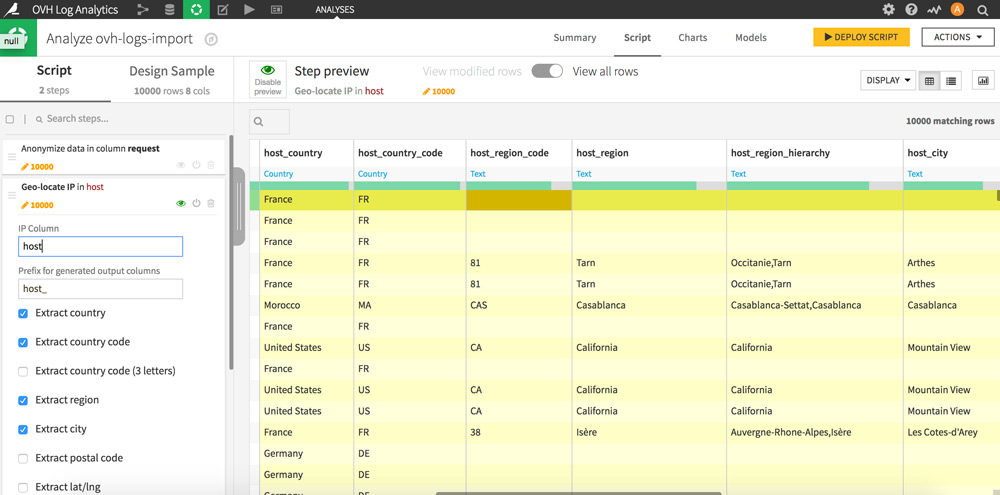
Vous venez de géolocaliser toutes les IP qui se sont connectées à votre site et connaissez ainsi la provenance de vos visiteurs par pays, région ou encore par ville. Pour avoir un aperçu de la répartition de l’origine géographique des visites, cliquez là encore sur l’intitulé de la colonne qui vous intéresse et sur « Analyse… ».
Filtrage de Google Bot dans les logs
Voici la partie qui devrait le plus plaire aux SEO !
Pour filtrer les hits de Google Bot dans les logs il existe 2 options :
La première est de cliquer sur l’intitulé de colonne « agent » puis de « Filtrer » sur la chaine de caractères « Googlebot », elle a cependant l’inconvénient de capter les fanfarons qui se font passer pour GBot… Pour connaitre les chaines complètes des user-agents de Google rendez-vous sur cette page.
La seconde méthode, plus fiable, consiste à filtrer les IP du GoogleBot en entrant manuellement le préfixe 66.249 (colonne « host »).
Une fois que vous avez choisi votre méthode, cliquez sur « +Add as a step » pour valider l’opération en suivant la même base de paramétrage que sur la capture d’écran ci-dessous.
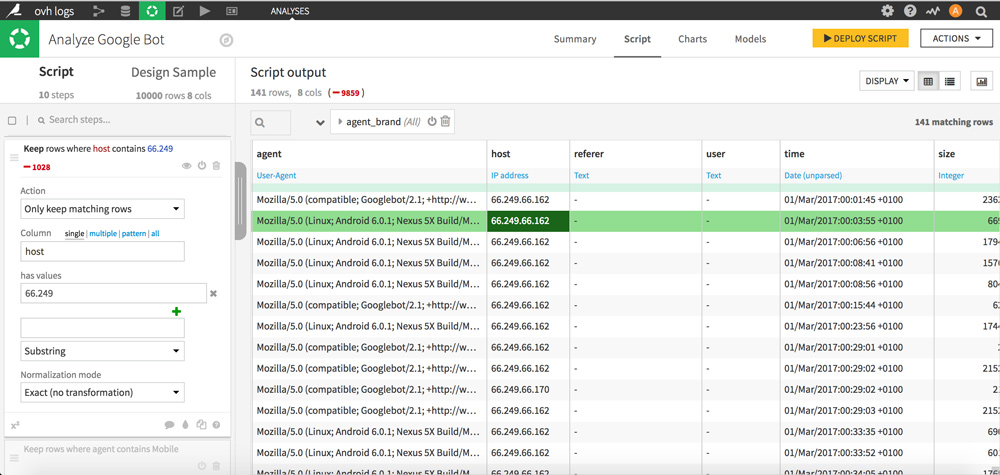
Il ne vous reste maintenant plus que des lignes basées sur le user agent Google Bot.
C’est une bonne base pour effectuer des analyses beaucoup plus fines et détaillées du comportement de Google Bot sur votre site : status codes rencontrés, pages les plus crawlées, etc.
J’espère que ces premiers « exercices » vous ont plu. Passons maintenant à une analyse de logs pour le SEO mais avant ça, préparons les logs.
PARTIE 2 : Préparation des logs
Nettoyage des logs pour une analyse SEO
L’intérêt ici est de ne garder que les logs les plus intéressants pour une analyse SEO. Nous allons donc supprimer les lignes qui concernent des appels de fichiers css, js, images, etc.
Créez une nouvelle analyse (comme vu dans la PARTIE 1 Vos première analyses) et choisissez la librairie « Filter rows/cell on value » qui se trouve dans l’ensemble « Filter data ».
Paramétrez ensuite le filtrage de vos logs de la façon suivante :
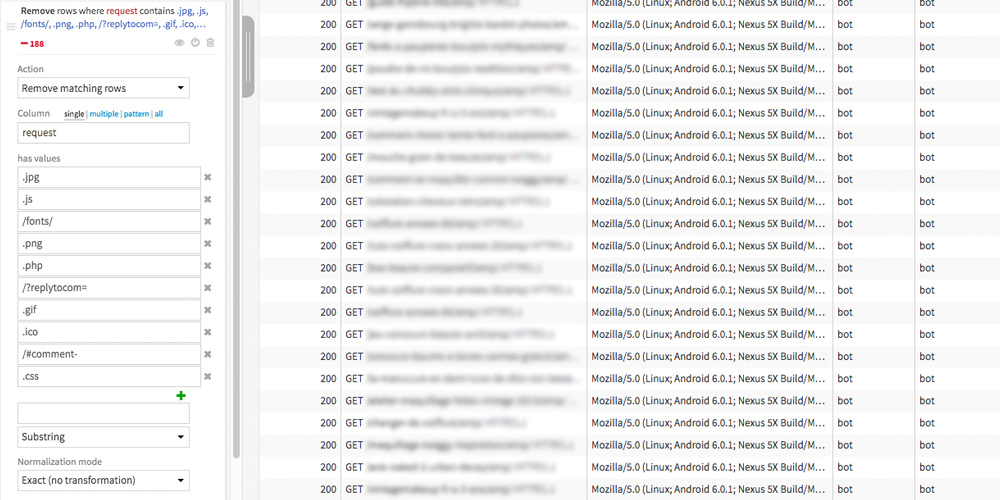
Les valeurs à filtrer peuvent varier selon le type de site que vous analysez. Ici les valeurs (« has values ») sont particulièrement adaptées à une analyse d’un site WordPress mais n’hésitez pas à parcourir votre dataset pour les compléter.
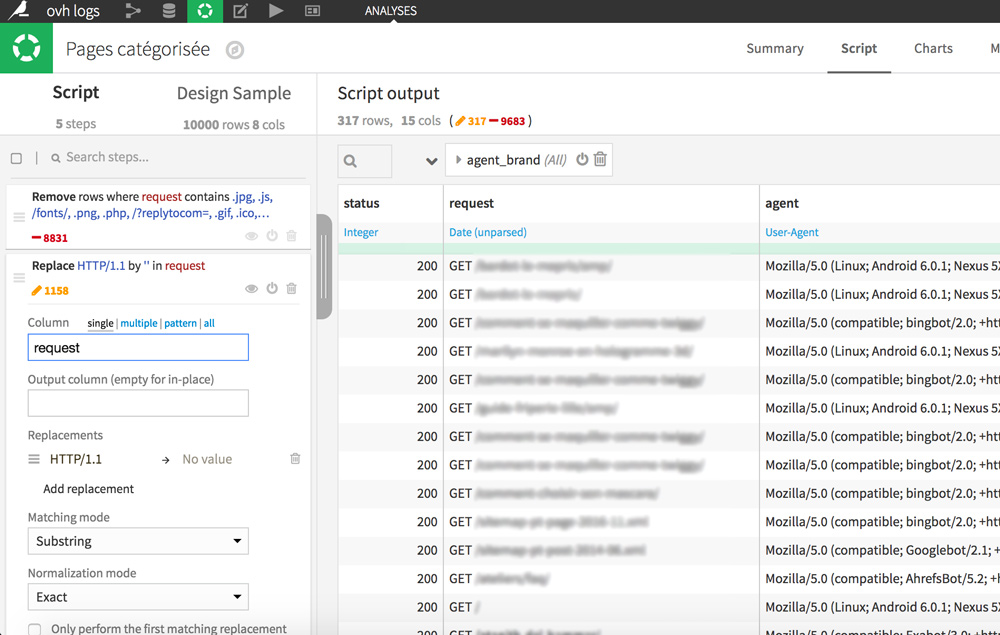
Enfin pour une meilleure lisibilité, nous allons supprimer le HTTP/1.1 à la fin des requêtes.
Dans la colonne request, double-cliquez sur n’importe quelle cellule contenant HTTP/1.1 puis sélectionnez « Replace HTTP/1.1 by … »
Filtrage des user agents des bots : GoogleBot, BingBot, etc
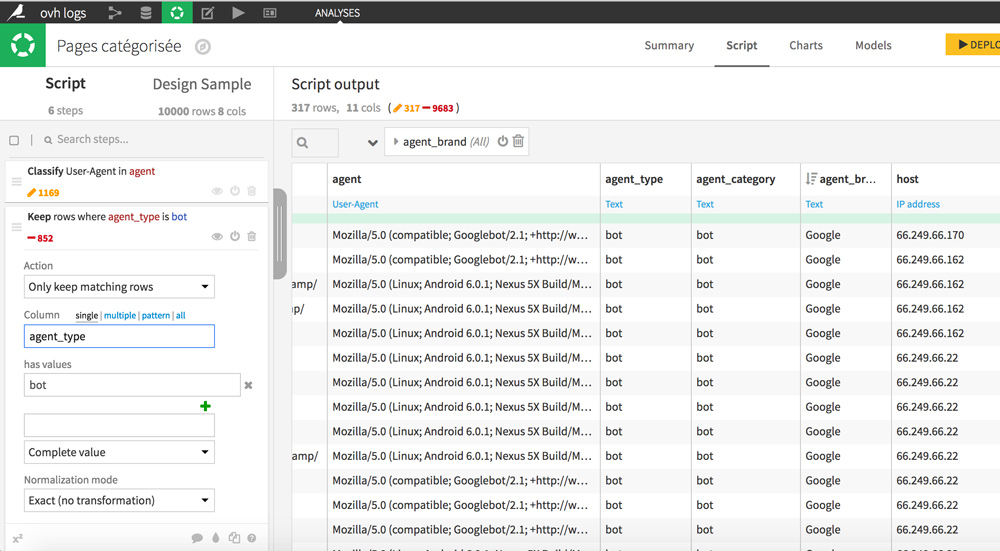
Commencez par classer les user agents par type afin que nous puissions ne garder que les bots. Pour cela cliquez sur l’intitulé de la colonne agent et sur « Classify user agent ». De nouvelles colonnes apparaissent avec des détails supplémentaires : agent_type, agent_category et agent_brand.
Pour ne garder que les lignes relatives aux bots cliquez sur une cellule contenant la valeur « bot » dans la colonne agent_type, puis sélectionnez « Keep only rows equal to bots. »
PARTIE 3 : Analyse de logs avancée
L’objectif de cette partie est d’étudier en profondeur le comportement des différents robots d’exploration : fréquence de visite des pages, status codes rencontrés, comportement d’exploration des pages mobiles.
Status code rencontrés par les bots
RDV dans l’onglet Charts.
Sur votre gauche se trouvent toutes les variables de votre dataset. Faites les glisser dans la partie droite sur X et Y afin de créer une visualisation de vos données.
La première visualisation est une vue macro des status codes rencontrés par les Bots : elle regroupe le nombre de passages de chaque bot sur le site ainsi que les status codes rencontrés.
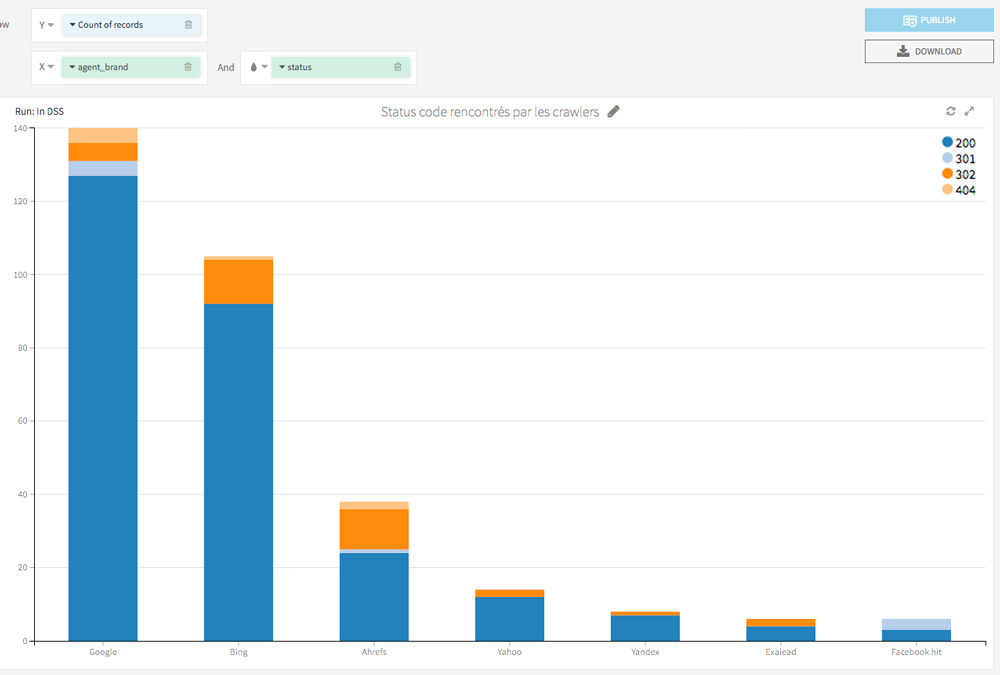
Ce type d’analyse vous plait ?
Passons à la vitesse supérieure.
Passage des bots par URL et par type de page
Analysons maintenant en détails le nombre de passages de tous les Bots sur chacune de vos URL afin de détecter des paterns particuliers. Nous classerons aussi les pages selon si elles sont AMP ou non.
Commençons par créer un nouveau dataset basé sur nos précédents traitements (filtrage, nettoyage). Nous en aurons besoin pour le regroupement des hits par URL.
Pour cela, cliquez sur le bouton jaune en haut à droite DEPLOY SCRIPT. Nommez-le, choisissez son emplacement et son format (CSV) puis cliquez sur DEPLOY.
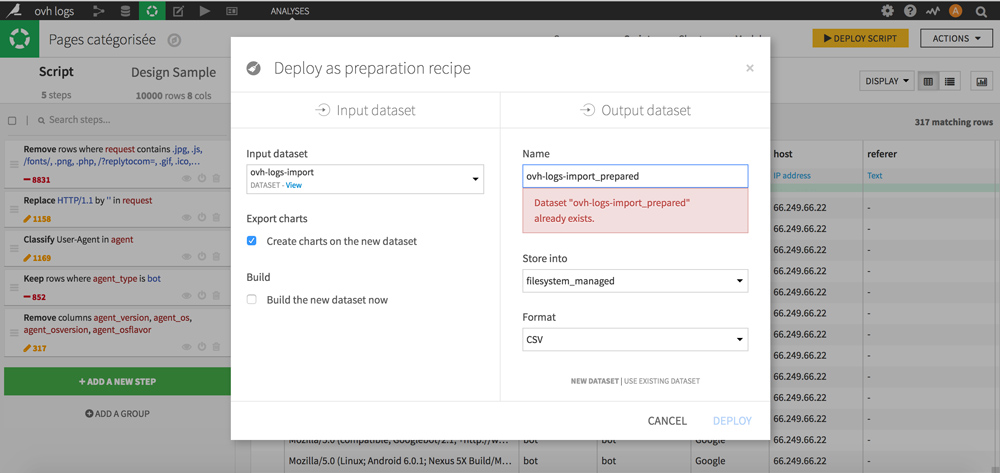
Votre nouveau dataset est prêt ?
RDV maintenant dans le FLOW (menu de Dataiku, en haut à gauche). Considérez le FLOW comme un historique de vos opérations.
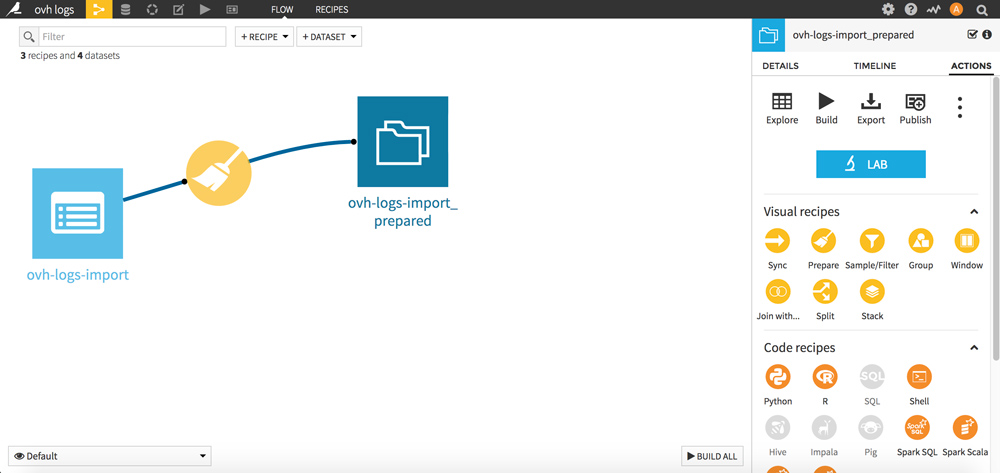
Nous allons maintenant regrouper les lignes par requêtes. L’objectif est de compter le nombre de passages de bots par URL.
Cliquez sur votre nouveau dataset puis dans la partie Visual recipes, cliquez sur le picto jaune « Group ».
Sélectionnez les Group Keys « request » et « agent_brand » puis validez votre nouveau dataset en cliquant sur le bouton RUN en bas.
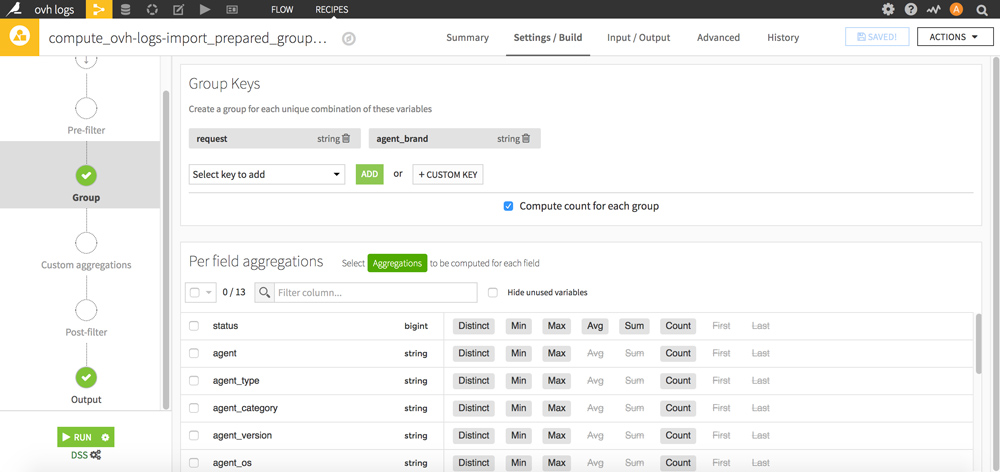
Retournez dans le FLOW : votre nouveau dataset apparait. Cliquez dessus puis sur le bouton « LAB » bleu à droite.
Une fenêtre apparait : cliquez sur « NEW Prepare data and build models » afin de démarrer une nouvelle analyse.
Avec une visualisation par tableau (onglet Charts), on peut en quelques clics générer un observatoire des passages de tous les bots sur chaque URL :
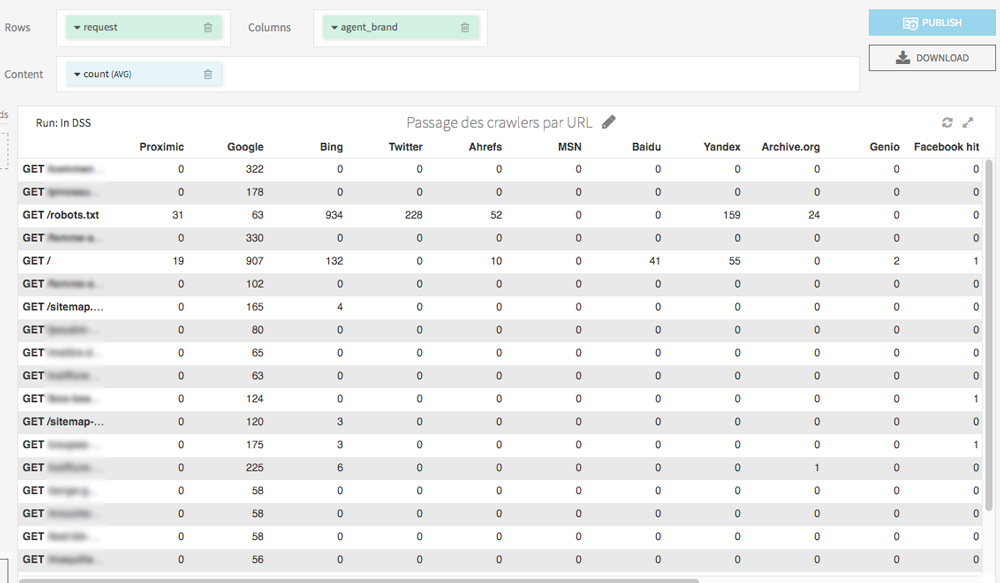
Toujours dans l’onglet Charts, en quelques glisser-déposer on peut facilement afficher les pages les plus consultées par les crawlers.
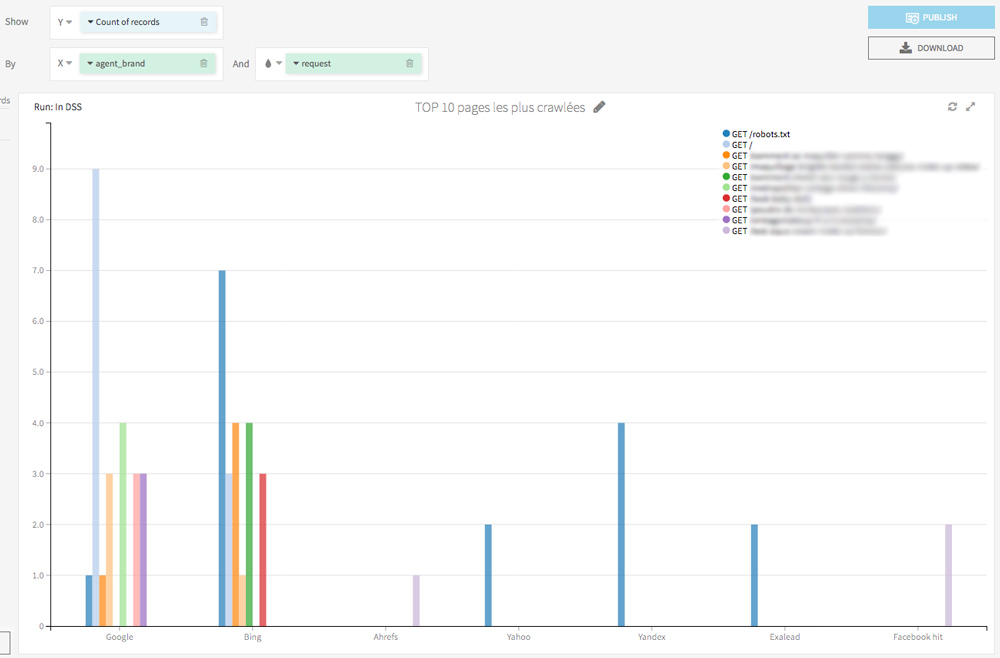
Je vous invite également à tester une visualisation des passages des différents bots par jour. Cela vous permettra de repérer des comportements anormaux (par exemple un bot qui arrête subitement de visiter certaines de vos pages) et aussi de connaitre la date de dernier crawl de vos URL.
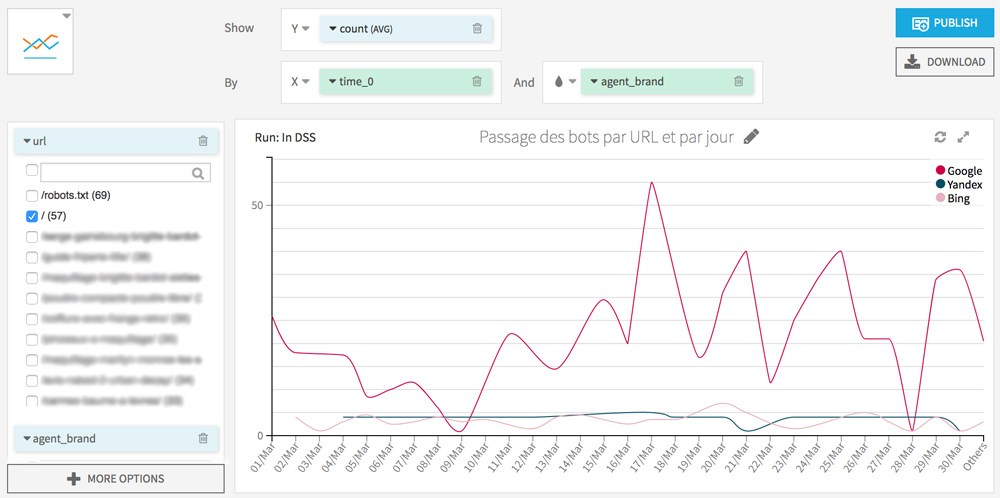
Comportements des bots sur les pages mobiles et AMP
Nous allons maintenant distinguer les URL AMP des URL non AMP.
Découpez la colonne request grâce à un Split avec delimiter / et précisez le nom de la colonne générée (dans le case Output columns prefix). Choisissez Output as Multiple columns et côchez Truncate. Passez le nombre de colonnes à garder à 1 et choisissez Starting from End.
Vous devriez obtenir quelque chose comme ça :
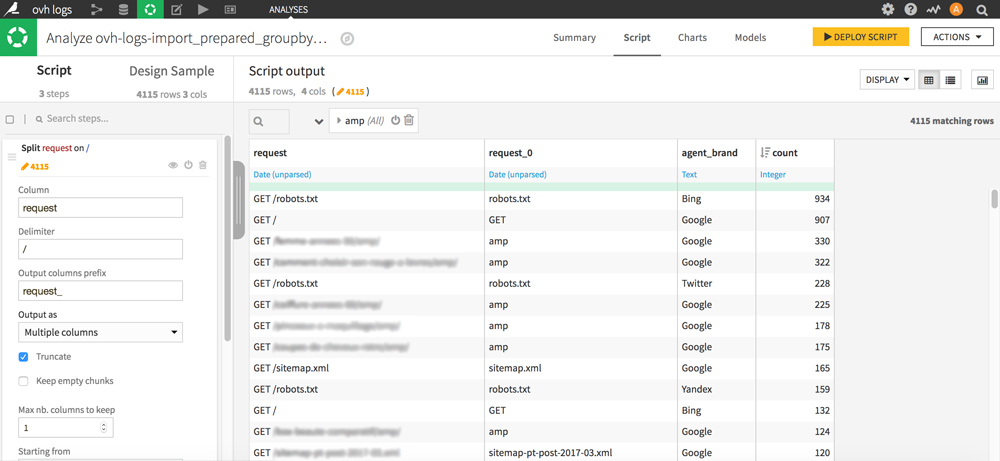
La colonne que vous venez de créer contient maintenant des morceaux d’URL dont « amp » qui nous intéresse ici particulièrement. Pour ne garder que « amp » et effacer le contenu des autres cellules sans pour autant effacer les lignes, procédez de la façon suivante :
Cliquez sur une cellule contenant amp, et double-cliquez sur « Keep only rows containing amp » puis dans la partie Script à gauche de l’écran, sélectionnez l’action « Clear non matching cells » avec la valeur amp.
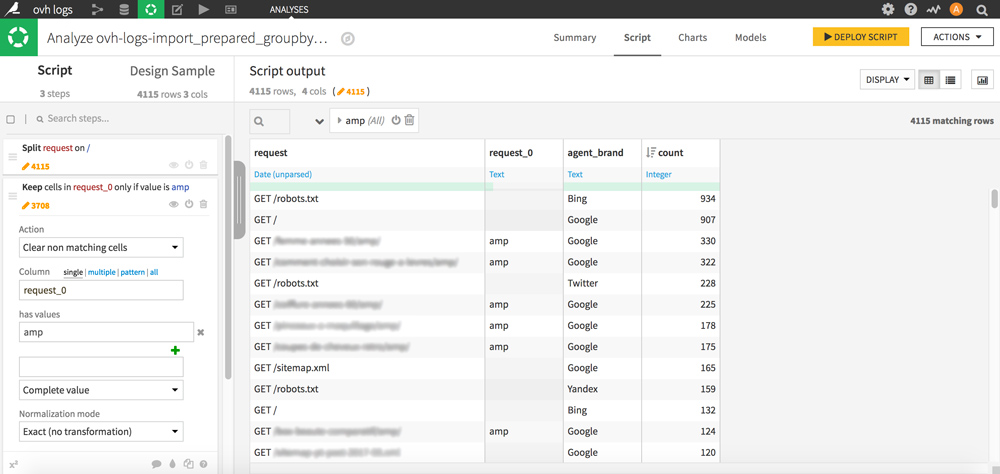
Votre colonne est maintenant nettoyée et vous permet en 1 coup d’œil de repérer les lignes de votre dataset correspondant à des pages amp, ce qui sera très pratique pour du filtrage.
Vous pouvez maintenant filtrer les passages de crawl par Bot (Google, Bing, yahoo, etc) et par type de page (amp / non amp) et même trier les lignes par nombre de passages pour une meilleure lisibilité.
Retournons dans l’onglet Charts pour visualiser la répartition du crawl sur les pages AMP vs non-AMP.
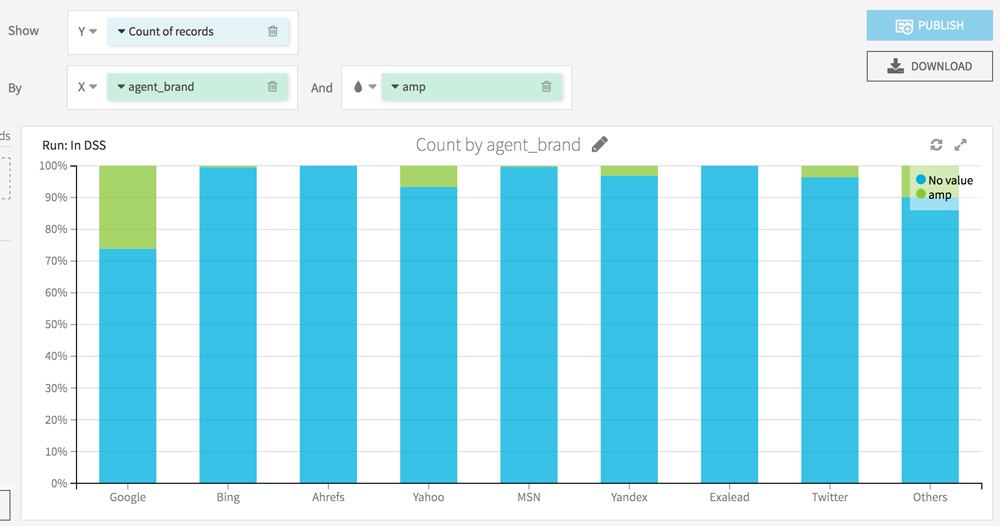
Pour aller plus loin, vous pouvez aussi agrémenter la visualisation de filtres : par catégorie de page, par type de bot (mobile vs non mobile).
Croiser les logs avec les données d’un crawl Screaming Frog
Faire une analyse croisée de logs
Une analyse croisée permet de détecter les zones du site où Googlebot ne passe pas et aussi de s’assurer qu’il passe du temps sur les bonnes pages. C’est une aide précieuse pour découvrir les pages orphelines ou encore les spider traps.
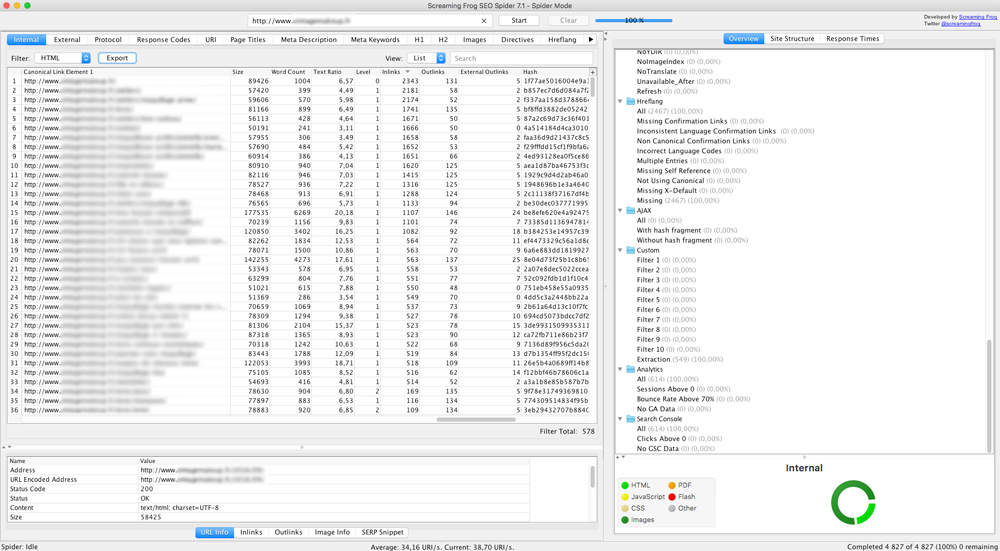
Commencez par crawler votre site avec Screaming Frog afin de récupérer des éléments onsite de chaque URL (level, inlinks, size, etc), filtrez les HTML et exportez les données au format .xlsx.
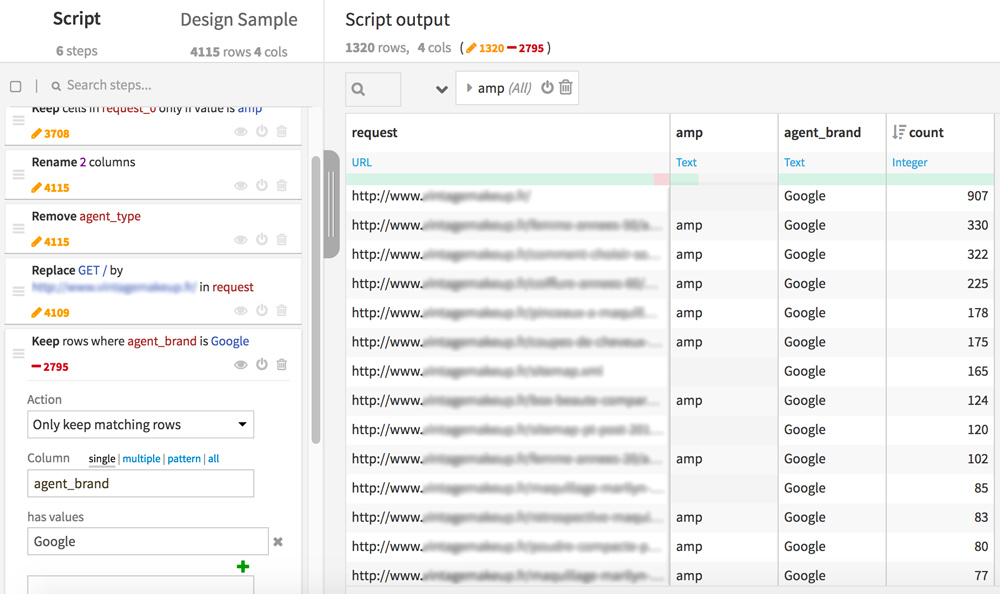
Dans Dataiku DSS, ré-ouvrez maintenant votre précédent dataset (celui avec les 4 colonnes request, amp, agent_brand et count). Nous allons le préparer pour le merge avec les données issues du crawl Screaming Frog. Créez maintenant une nouvelle Analyse.
Dans la colonne « request », remplacez « GET / » par votre nom de domaine complet tel qu’il apparait dans votre fichier internal_html de Screaming Frog. Cette étape va nous permettre de faire correspondre les lignes entre les 2 datasets.
Pour cette analyse, vous pouvez aussi conserver uniquement les lignes correspondantes à GoogleBot (Keep rows where agent_brand is Google)
Cliquez sur DEPLOY SCRIPT en haut à droite. Une nouvelle page s’ouvre, cliquez sur RUN afin de créer un nouveau dataset basé sur vos derniers traitements, nous l’appellerons « ovh_crawl_logs_ready ».
Passons au regroupement du fichier de logs avec le crawl Screaming Frog. RDV maintenant dans le FLOW
Cliquez sur + DATASET et uploadez votre fichier Screaming Frog.
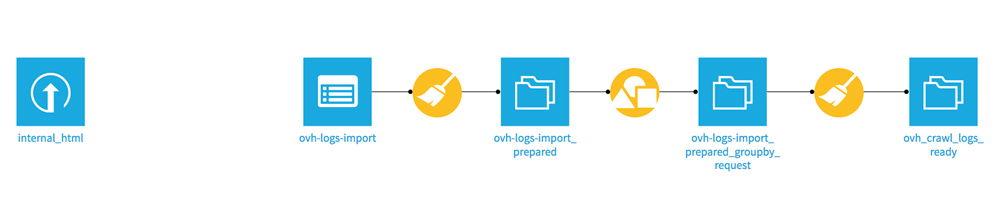
Avant de pouvoir joindre les 2 fichiers et conserver toutes les données des 2 datasets, il faut les stocker dans une base de données SQL PostgreSQL comme expliqué sur le forum de Dataiku.
Cliquez sur votre dataset ovh_crawl_logs_ready puis sur Export (dans la sidebar de FLOW). Une fenêtre s’ouvre, RDV dans l’onglet EXPORT TO DATASET. Donnez un nouveau nom à votre dataset (ovh_crawl_logs_ready_postgresql), puis choisissez Store into PostgreSQL.
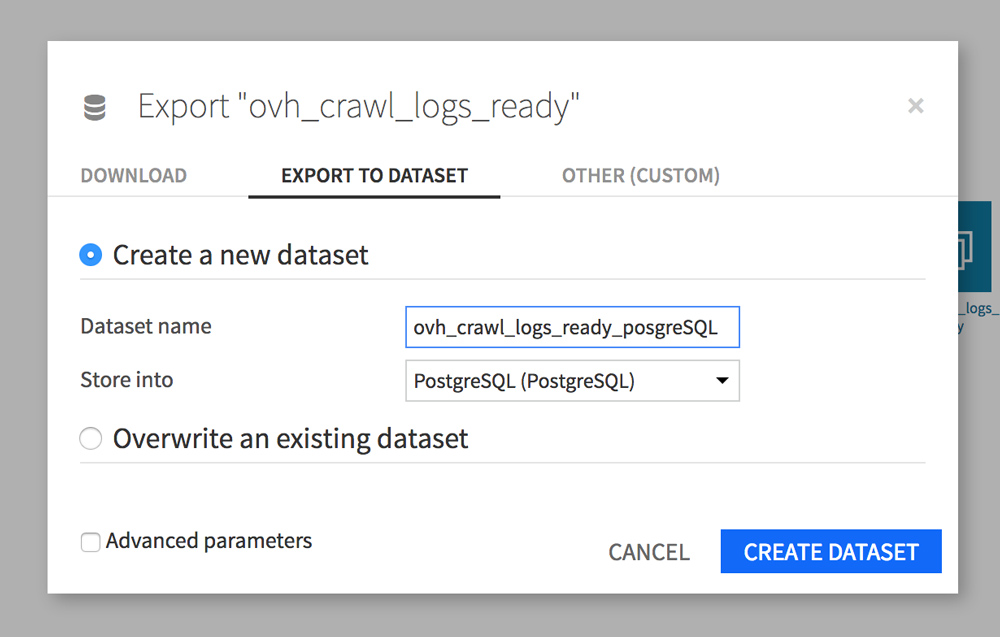
Répétez l’opération avec votre dataset Screaming Frog « internal_html ».
Une fois la création de vos bases PostgreSQL terminée, cliquez sur votre nouveau dataset « ovh_crawl_logs_ready_postgresql » pour faire apparaitre la sidebar de FLOW.
Dans la zone Visual recipes de la sidebar, cliquez sur « Join with ».
Une fenêtre apparait. la valeur de First input dataset est de base « ovh_crawl_logs_ready_postgresql ». Pour le Second input dataset, choisissez internal_html_postgreSQL puis cliquez sur CREATE RECIPE. Une nouvelle page apparait.
Passons au paramétrage du merge.
Dans l’étape Join, Cliquez sur la ligne qui relie Adress à request. Une fenêtre apparait. Cliquez sur l’onglet JOIN TYPE et sélectionnez Outer join afin de garder toutes les lignes qui correspondent entre les 2 datasets mais aussi les lignes qui ne correspondent pas.
Cela nous permettra par exemple de découvrir les pages orphelines (pages vues par les bots mais non liée sur le site) ou les pages non crawlées par Google alors qu’elles sont liées sur le site.

Afin d’accélérer les traitements, nous allons filtrer certaines colonnes. Pour cela passez à l’étape Selected columns.
Les données les plus intéressantes de votre fichier Screaming Frog se trouvent dans les colonnes Adress, Size, Word_Count, Text Ratio, Level, Inlinks, Outlinks, External Outlinks, Response Time. Vous pouvez leur ajouter un préfixe (ex : SF_) pour faciliter la lecture dans votre futur dataset.
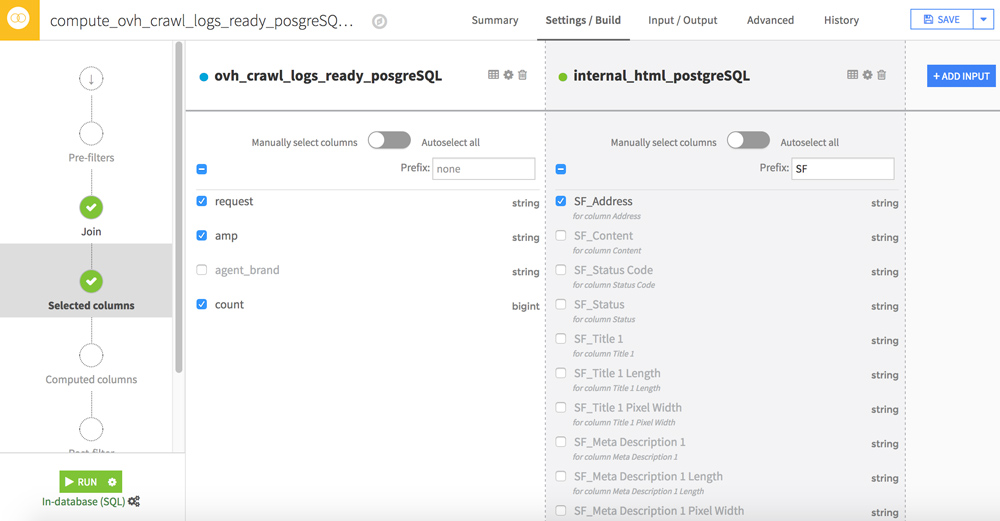
Cliquez sur RUN afin de lancer le merge des deux datasets.
Vous êtes maintenant prêt pour une analyse croisée logs / crawl ! Ouvrez votre nouveau dataset.
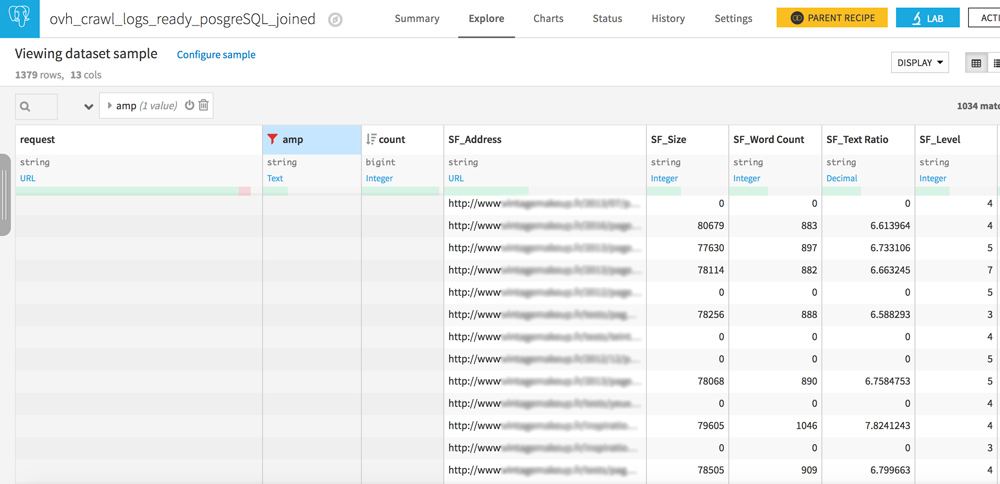
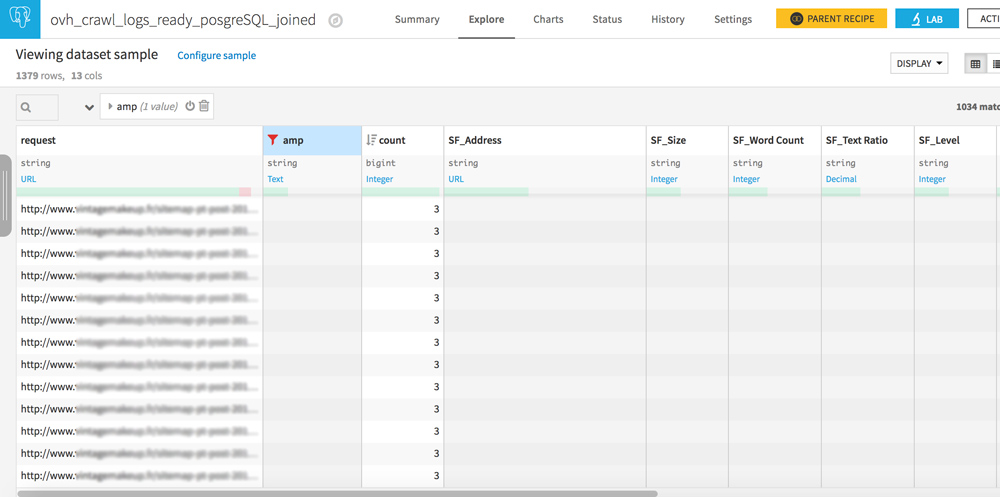
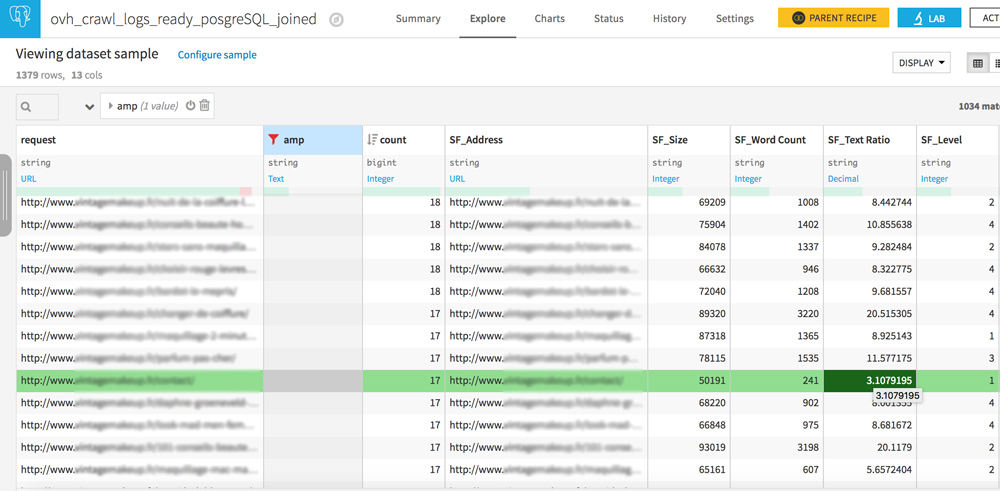
Pages orphelines et pages jamais crawlées
Votre dataset comporte 2 colonnes similaires : request et SF_Address.
Jouez avec les filtres pour créer les 3 configurations suivantes :
- request vide / URL dans SF_Adress : pages jamais crawlées mais bien liées sur votre site
- URL dans request / URL dans SF_Address : tout est OK, les crawlers voient des pages qui sont bien liées sur votre site
- URL dans request / SF_Address vide : il s’agit des pages orphelines, des pages qui ne sont plus liées sur votre site mais que les robots consultent quand même. Si vous avez entendu parler de crawl budget, la réduction de ces pages doit faire partie de votre stratégie SEO.
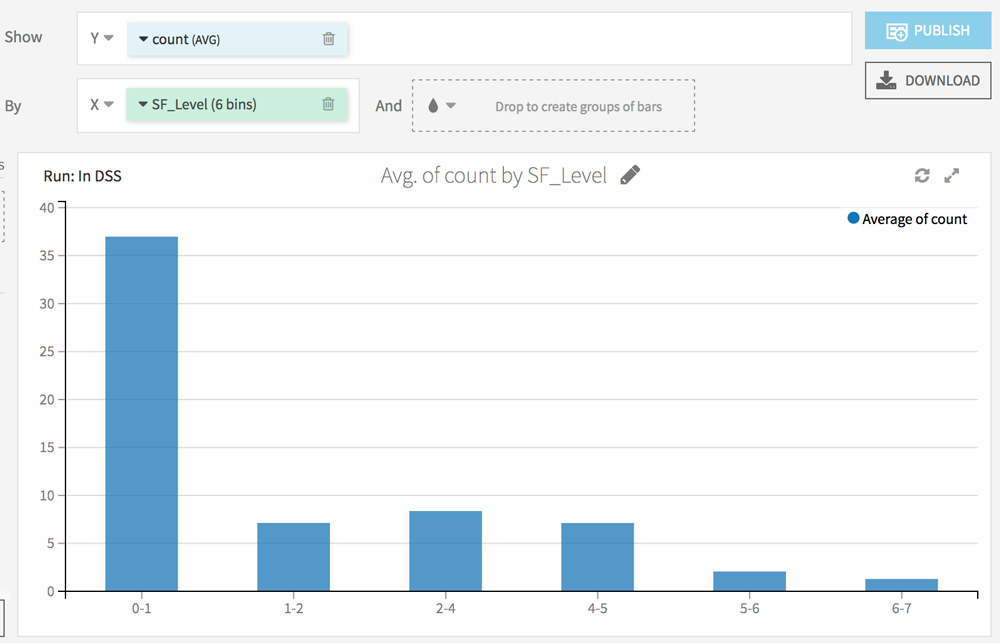
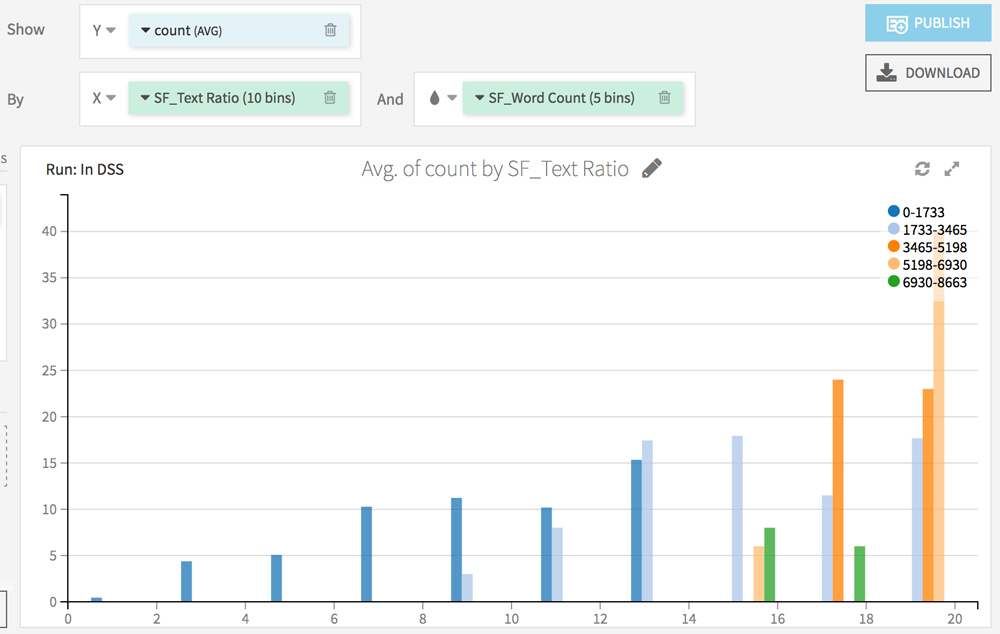
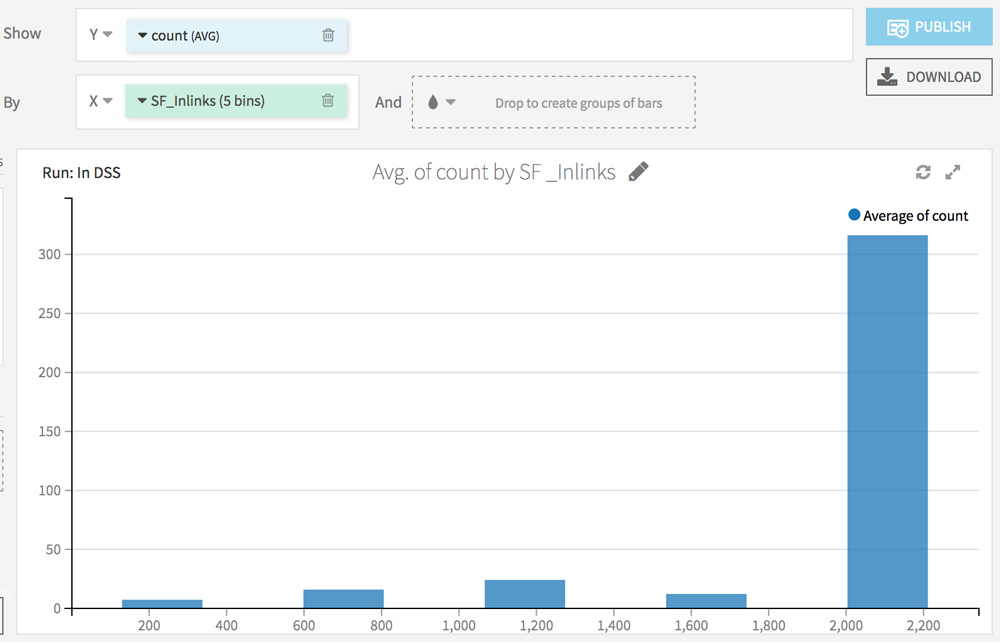
Trouver vos propres corrélations entre logs et crawl
RDV dans l’onglet Charts. L’idée ici est d’analyser l’impact de chaque facteur récolté via l’analyse Screaming Frog sur la fréquence de passage du crawler.
Choisissez count (AVG) sur l’axe Y et testez différentes combinaisons sur l’axe X.
Voici quelques idées :
La suite ?
Les analyses que nous avons fait jusqu’ici sont des analyses descriptives.
Dans un prochain article, nous utiliserons Dataiku DSS pour faire de la prédiction grâce aux algorithmes de Machine Learning.
N’hésitez pas à poser vos questions en commentaires 😉 J’enrichirai l’article selon vos retours !
Suivez-moi sur Twitter pour être informé des mises à jour de l’article :
[New TUTO #SEO] Analyser les logs d’un hébergement web @ovh_fr avec @dataiku (outil datascience gratuit) https://t.co/xd74798Mx4
— Rémi Bacha (@Remibacha) 18 avril 2017
Merci à Jérémy Grèze (de Dataiku) pour son aide dans la création de ce guide.
L’utilisation d’un CDN comme cloudfare modifie toutes les adresses IP entrantes, une astuce pour les sites utilisant un CDN de ce type ?
Hello,
Oui, un CDN comme Cloudflare fonctionne comme un proxy et masque l’adresse IP entrante. Cloudflare fait suivre l’IP dans le header. Il faut ainsi configurer le serveur pour enregistrer ce header dans les logs. Cf: https://support.cloudflare.com/hc/en-us/sections/200805497-Restoring-Visitor-IPs
Un hébergement web OVH (mutualisé) n’est pas aussi finement paramétrable. A noter que OVH offre son propre CDN, ce qui peut résoudre le problèmes si on veut utiliser les logs du mutu et un CDN.
Sur l’hébergement web OVH, lorsque tu utilises un CDN, le rewrite de l’IP dans les logs est automatique : tu vois bien l’IP de l’utilisateur.
Salut Rémi,
Es-tu sûr de cela ? Dans différents logs analysés, je n’ai jamais les IP des GoogleBot (66.249.*.*) lorsque les sites sont derrière CloudFlare.
PS : bravo pour tes articles en général !
Thx pour ton article ,
Pas facile de trouver des cas concrets en Français sur Dataiku mais le logiciel a l’air prometteur.
Au plaisir de te lire
Seoxis
Merci ! Tu trouveras un autre cas d’utilisation en vidéo ici : https://remibacha.com/data-science-seo/
Hello,
J’utilise la version en ligne (Trial 14 days).
Quand je met mon login/mdp, domaine etc, ça me met ça : Test failed: Authentication error. Check the login and the password.
(le login et mdp sont bons pourtant)
Hello,
je ne connais pas la version en ligne mais j’imagine que les connecteurs fonctionnent de la même manière que sur la version locale. Tu peux contacter Jéremy Greze (@jeremy_gr sur Twitter), c’est lui qui a dev le plugin OVH. Tiens-moi au courant si tu en sais plus 😉
Salut Rémi et merci pour ce tuto très détaillé, c’est vraiment intéressant.
En revanche, j’ai une erreur à ce stade : « Sélectionnez les Group Keys « request » et « agent_brand » puis validez votre nouveau dataset en cliquant sur le bouton RUN en bas. »
Il est en effet impossible de sélectionner deux Group Keys à priori, sais-tu si cela provient du soft, du tuto, ou si j’ai mal fait quelque chose ?
Merci,
Petit supplément d’info pour celles et ceux qui seraient intéressés par l’installation sur Windows 10.
forums.virtualbox.org/viewtopic.php?f=1&t=62339
Et surtout par le bas de page :
1. To check the status of Hyper-v in Windows 10, | Run | OptionalFeatures.exe, and look for the « Hyper-V » option. The box should be empty, not checked or shaded. Make sure to fully power down and reboot the host after changing this setting.
J’en suis à l’étape Connexion avec OVH mais çà coince (même message que Rémi Beaumont).
J’attends d’être en relation avec @jeremy_gr sur Twitter pour en savoir plus.
Merci en tout cas de ce partage très intéressant.